Bagging & Boosting
主要思想就是 寻找多个识别率不是很高的弱分类算法比寻找一个识别率很高的强分类算法要容易得多 (三个瓜皮匠, 赛过诸葛亮), AdaBoost 算法的任务就是找几个精确度不是那么高的弱分类算法,让它们一起合作形成一个强分类算法,从而提高准确率。
Bagging (Bootstrap aggregation):
Bootstrap就是鞋带,帮助提鞋子的纽带;
Aggregating是指聚集.
机器学习的Bagging方法指对多个学习器进行独立的学习、最后汇总的方法。
算法流程:
- (A) 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。k个训练集之间是相互独立的.
- (B) 每次使用一个训练集得到一个模型,k个训练集就能得到k个模型。(注:这里并没有具体的分类算法或回归方法,可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- (C) 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
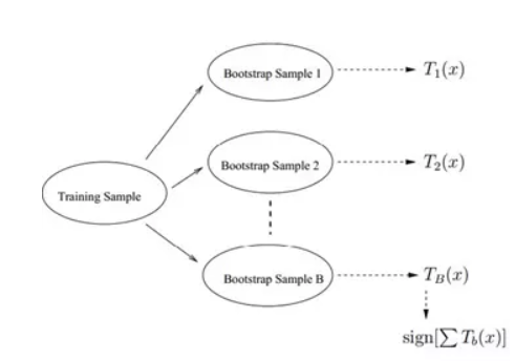 注:Bagging是一种方法,其中的单个模型不一定是决策树,可以是别的分类器.
注:Bagging是一种方法,其中的单个模型不一定是决策树,可以是别的分类器.
Boosting:
Boosting是增强、强化的意思,是指对多个学习器依次进行学习、逐渐增强效果的算法。
其主要思想是将弱分类器一步一步训练,组装成一个强分类器。在PAC(概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。
关于Boosting的两个核心问题:
- 在每一轮如何改变训练数据的权值或概率分布?
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。 - 通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
而boosting树通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
boosting在选择hyperspace的时候给样本加了一个权值,使得loss function尽量考虑那些分错类的样本. boosting重采样的不是样本,而是样本的分布,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合),分类器相当简单。
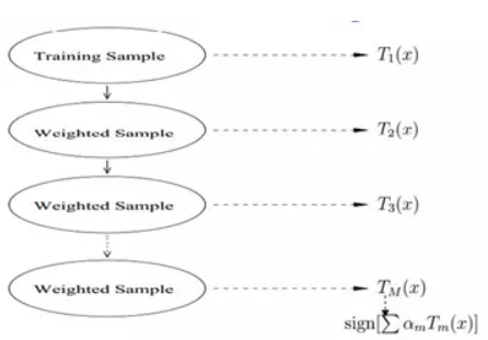 注:Boosting 是一种思想,具体方法可是是AdaBoosting, GDBT, 这些方法主要解决如何从前一个模型到下一个模型的问题。
注:Boosting 是一种思想,具体方法可是是AdaBoosting, GDBT, 这些方法主要解决如何从前一个模型到下一个模型的问题。
Bagging 和 Boosting对比
- 样本选择上:
- Bagging:训练集是在原始集中有放回选取的,选出的各个训练集之间是独立的
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整
- 样例权重:
- Bagging:使用均匀取样,每个样例的权重相等
- Boosting:根据错误率不断调整样例的权值,错误率越小则权重越大
- 预测函数:
- Bagging:所有预测函数的权重相等
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
- 并行计算:
- Bagging:各个预测函数可以并行生成
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
随机森林: Random Forest
RF就是使用决策树加在Bagging框架中,利用多棵树对样本进行训练并预测的一种分类器。
随机森林就是由多棵CART(Classification And Regression Tree)构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。
在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回的抽取的。
- 从原始训练集中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构造k棵分类回归树;
- 在训练k棵树时,并不是每个训练过程都选择所有特征进行训练。设有n个特征,则在每一棵树可用的特征是随机从n个中选择m个,也就是说每棵树都掌握一小部分的特征的分类效果;
- 每棵树最大限度地生长,不做任何修剪;
- 将生成的树组成随机森林,用随机森林对新的数据进行分类,分类结果按树分类器投票决定。
Random Forest与Bagging的区别在于:Bagging每次生成决策树的时候从全部的属性里面选择,而RF是随机从全部集合里生成一个大小固定的子集,相对而言需要的计算量更小一些。
总结:这两种方法(RF, Bagging)都是把若干个弱分类器整合为一个强分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高了原单一分类器的分类效果,但是也增大了计算量。
- Boosting通过将若干个弱分类器合成一个强分类器,主要降低Bias。因此GBDT中每棵树的深度都很浅,通过boosting消除单棵树的bias;
- Bagging通过将多个弱分类器取平均,主要降低Variance。因此RF每棵树都是充分学习的(过拟合的)树,通过bagging消除单棵树的variance。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
级联回归:
Dlib库里面的face landmark detector就是利用Random Ferns的级联回归实现的。(详细介绍会放在后面的blog里面)
通过一次一次的回归将mean shape回归到正确的地方,回归过程如下:
- 提取特征 (Pose-indexed point features, 2010);
- 根据特征训练回归函数(线性回归, CART, 随机森林等, Random Fern Regressor) 回归出这一阶段的偏移量;
- 然后将mean shape加上此偏移量;
- 重复以上过程直到迭代上限或shape错误率不再下降。
一些讨论:神经网络能否代替决策树算法 (知乎回答:https://www.zhihu.com/question/68130282)
先要说明决策树就是决策树,随机森林和xgboost的性能提升主要是来自于集成学习。所以,我们扩展一下题目把对比延伸到:
- 单棵决策树,如比较常见的C4.5等
- 以决策树为基模型的集成学习算法(Ensemble Tree),如RF, gradient boosting, xgboost
- 神经网络,包括各种深度和结构的网络
单棵决策树的用途已经比较有限了,已经基本被集成决策树代替。而决策树集成模型和神经网络有不同的使用场景,不存在替代一说。
- 如果不强调绝对的解释度,尽量避免单棵决策树,用集成树模型
- 在集成数模型中,优先推荐使用xgboost
- 在中小数据集上,优先选择集成树模型。大数据集上推荐神经网络
- 在需要模型解释度的项目上,优先使用树模型
- 在项目时间较短的项目上,如果数据质量低(大量缺失值、噪音等),优先使用集成树模型
- 在硬件条件有限及机器学习知识有限的前提下,优先选择树模型
- 对于结构化较高的数据,尤其是语音、图片、语言,优先使用神经网络模型(往往其数据量也较大)
单棵决策树 vs. 集成学习
决策树是1963年被 Morgan和Sonquist提出的,通过类树的结构实现分类和回归。一般认为决策树模型:
- 易于使用和解释,单棵的决策树很容易进行可视化和规则提取
- 自动实现特征选择: 通过计算节点分裂时” impurity reduction” 与“pruning”
- 预测能力有限,无法和强监督学习模型相提并论
- 稳定性低(stability)方差高(variance),数据扰动很容易造成决策树表现有很大的变化
随机森林是Breiman提出的,模型使用集成的学习来降低单棵决策树中的高方差(high variance)从而提高了整体的预测能力。而gradient boosting machine(GBM)和xgboost分别是在2001年和2014年提出的。鉴于两者比较相似放在一起讨论,这两个模型:
- 和随机森林的并行学习(parallel learning)不同,使用串行学习(sequential learning)不断地提高的模型的表现能力降低偏差(bias);
- 在进行预测分类的时候非常快且对于储存空间的要求低;
- boosting这个学习方法可以看成一种l1正则化来防止过拟合,因此模型不容易拟合;
- 单纯对比GBM和xgboost的话,它们的分类性能接近,xgboost有一个额外的正则项进一步降低过拟合。而xgboost的速度更快,往往更适合较大的数据集。
根据各种各样实践和研究来看,随机森林、GBM和xgboost都明显优于普通的单棵决策树,所以从这个角度来看,单棵决策树可以被淘汰了。而单棵决策树最大的护城河在于,它可以被很轻松的可视化甚至是提取分类规则。而集成学习在这一点是很难做到的。而可解释化对于工业界很多时候是很重要的,从这个角度来看,决策树还有一点点立身之本。但这个使用的前提是,一定一定要确定决策树的表现不错(比如查看交叉验证的结果)再来可视化和规则提取,不然很有可能提取到无效甚至是错误的规则。
集成树模型 vs. 神经网络
神经网络最大能力就是从复杂的数据中进行特征表示,也被认为可以近似表示任何函数(假设有特定多的node),现在火爆的深度学习就是深度较大的神经网络的特定叫法。神经网络和集成树模型在以下几点上有较大的不同:
- 从数据量上来讨论:神经网络往往需要较大的数量,而小数据集上树模型有明显的优势。常常有人问,多小才算小?这也同时需要取决于特征的数量。但一般来说,几百几十个数据的情况下神经网络很难表现良好。
- 从特征工程角度看:神经网络需要更苛刻的数据准备工作,而树模型一般不需要以下步骤:
- 缺失数据弥补(missing value imputation)
- 数据类型转化(categorical to numerical):把类别数据变为数字型
- 数据缩放(data scaling):把不同范围的数据归一到[0,1]或者投射到正态分布上
- 更多的参数调整:比如初始化权重,比如选择合适学习率等
- 从调参难度来看:集成树模型远低于神经网络。大部分的集成树模型也仅需要:(i)基学习器数量 (ii) 考虑的特征数 (iii) 最大深度 等。神经网络的调参惨剧已经没什么好说的,这点上和树模型差距非常大
- 从模型解释度来看:集成树模型的解释度一般更高,比如可以自动生成特征重要性(feature importance)。神经网络的特征虽然也可以一定程度上进行分析,但不大直观。再早年间,在神经网络上使用包裹式(wrapper)方法,每次加1或者减1个特征进行特征排序也曾存在过,远不如集成树模型的嵌入式(embedded)特征选择来的方便和直观。
- 从模型预测能力来看:抛去调参的难度差异不提,大中型数据上的表现较为接近。随着数据量增大,神经网络的潜力越来越大
- 从项目周期来看:因为在各个方面神经网络都需要更多的时间,因此其需要的总时间往往远大于决策树集成,更别提还需要很好的硬件支持,如GPU。
一般来说,在小数据量多特征下,集成的树模型往往优于神经网络。随着数据量增大,两者表现趋于接近,随着数据量继续上升,神经网络的优势会逐步体现。这个跟很多答主提到的一样:随着数据量上升,对模型能力的要求增加而过拟合的风险降低,神经网络的优势终于有了用武之地而集成学习的优势降低.
综上来看,大部分项目建议使用集成决策树,首推xgboost,速度快效果好用时少。特定的复杂且数据量大的项目,建议还是老实的为神经网络调参. 所以暂时来看,已经被替代的是单棵决策树,而集成决策树还非常重要甚至变得更为重要。在短时间内,看不到集成决策树模型被替代的可能。
目前,几乎所有的深层神经网络都使用具有随机梯度下降的反向传播作为训练过程中更新参数的幕后主力军。实际上,当模型由可微分量(例如,具有非线性激活函数的加权和)组成时,反向传播似乎仍是当前的最佳选择。其他一些方法如目标传播已经被作为训练神经网络的替代方法被提出,但其效果和普及还处于早期阶段。例如研究表明,目标传播最多可达到和反向传播一样的效果,并且实际上常常需要额外的反向传播来进行微调。换句话说,老掉牙的反向传播仍然是训练神经网络等可微分学习系统的最好方法。
另一方面,探索使用非可微模块来构建多层或深度模型的可能性的需求不仅仅是学界的兴趣所在,其在现实应用上也有很大的潜力。例如,基于树的集成(例如随机森林或梯度提升决策树仍然是多个领域中建模离散或表格数据的主要方式,为此在这类数据上使用树集成来获得分层分布式表征是个很有趣的研究方向。在这样的案例中,由于不能使用链式法则来传播误差,反向传播不再可行。这引发了两个基本的问题:首先,是否可以用非可微组件构建多层模型,从而中间层的输出可以被当作分布式表征?其次,如果是这样,如何在没有反向传播的帮助下,联合地训练这种模型?
- Zhou 和 Feng 提出了深度森林框架,这是首次尝试使用树集成来构建多层模型的工作。具体来说,通过引入细粒度的扫描和级联操作(cascading operation),该模型可以构建多层结构,该结构具备适应性模型复杂度,且能够在多种类型的任务上取得有竞争力的性能。由于很多之前的研究者认为,多层分布式表征可能是深度神经网络成功的关键,为此我们应该对表征学习进行这样的探索。
- 该研究力求利用两个方面的优势:树集成的出色性能和分层分布式表征的表达能力(主要在神经网络中进行探索)。具体来说,本研究提出了首个多层结构,每层使用梯度提升决策树作为构造块,明确强调其表征学习能力,训练过程可以通过目标传播的变体进行联合优化。该模型可以在有监督和无监督的环境下进行训练。本研究首次证明,确实可以使用决策树来获得分层和分布式表征,尽管决策树通常被认为只能用于神经网络或可微分系统。