MobileNet
MobileNet is designed for CNN deployment in embedded devices, such as MCU, Mobile phone. It has proven faster speed on inference with little accuracy drop. (compared with other nets such as ResNet, VGG…)
I have had used VGG16 for a image classification task before and deployed on IOS, but hardly reach any real-time demands (512Mb in model size and ~1s inference time)
Scientists have been working on optimization/efficiency on CNN, lots of idea ranging from nets-structure(prone) to hardware acceleration…
MobileNet’s motivations:
- Limitation on computing resources especially embedded devices;
- State-of-the-art networks have huge redundancy beacause of sparse connection (ResNet ~ 70% Redundancy);
- Before MobileNets, using Hash, Hoffman encode to train a lite model.
MobileNet V1:
Structure features:
- Separable convolution [Depthwise+Pointwise]; (深度可分离卷积)
- 28 Layer (BatchNorm + ReLU after each layer).
- Global hyper parameters;
- (1) width multiplier: α (Thinner model)
- i. α=1, Regular MobileNet
- ii. α<1, computation/parameters -> α^2
- (2) resolution multiplier: ρ (reduce representation)
- i. ρ=1, Regular MobileNet
- ii. ρ<1, computation/parameters -> ρ^2
Note:(1)(2)may drop the performance, so needs to consider the trade-off between accuracy & model size;
- (1) width multiplier: α (Thinner model)
MobileNet V1 single path network, no feature re-use. (It’s important to address that ResNet and DenseNet proven feature re-use can be valuable)
MobileNet V2:
MobileNet v2’s motivations:
- Data collapse:(数据坍塌)
- ReLU results in low-dimentional data collapse, so highly recommanded not use ReLU after feature map if channel is few;
- Solution: Linear Bottleneck. (non-linear activate func make data loss, so not use ReLU in Bottleneck layers)
- Feature degradation: (特征退化)
- If a node’s weight get updated to 0, this node cannot be updated further; (Derivatives of ReLU)
- Solution: Apply skip learning in Thinner bottleneck layers. (Feature-reuse, proven ResNet outperformed VGG)
Structure features:
- Separable convolution; (same as v1)
- Feature-reuse + Linear bottleneck (No ReLU in feature map)
- Inverted residual block:Feature map -> pointwise conv (increase dimension) -> ReLU (feature protection)
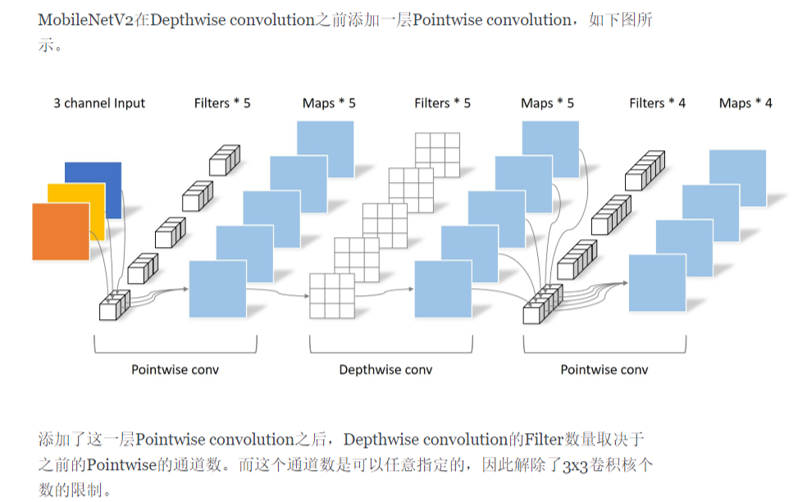
Residual Module vs Inverted Residual Module:
- Apply skip leaning on board layers before bottleneck.
- Directly skip learning connected on bottleneck.
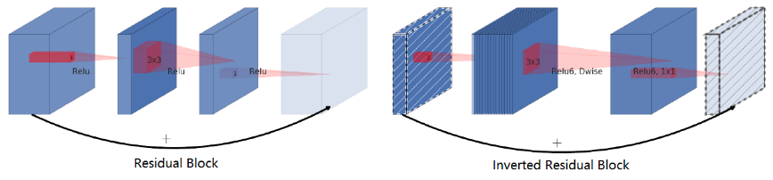
MobileNet V1, MobileNet V2, ResNet:
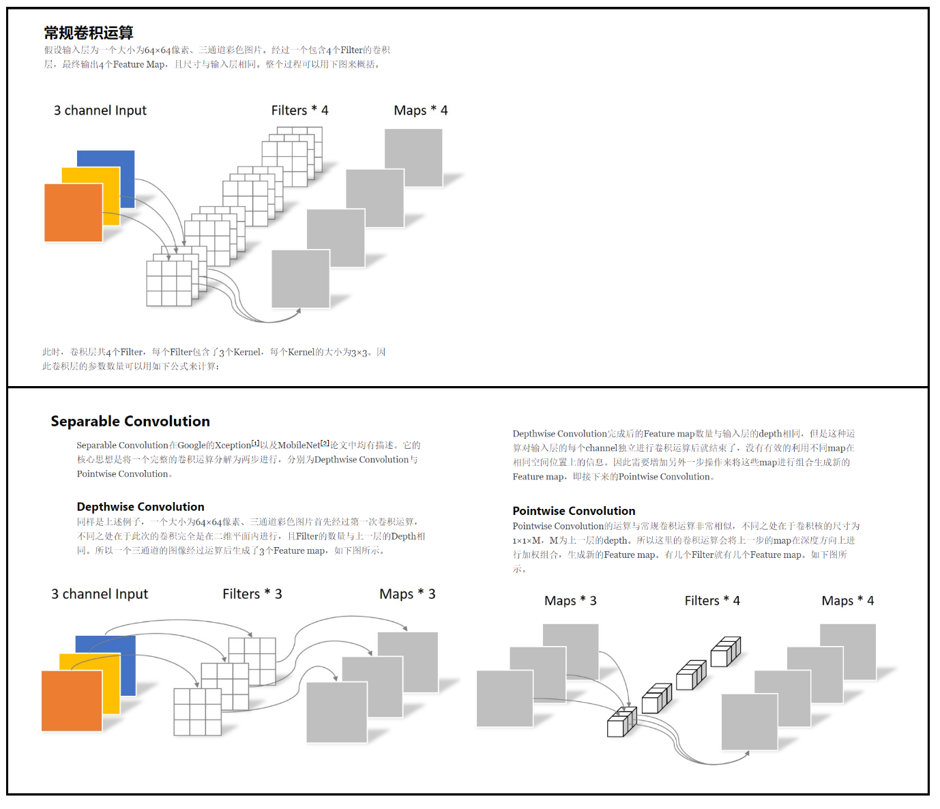
- v2在原有的dw之前加了一个pw专门用来升维。这么做是因为dw,给多少通道就输出多少通道,本身没法改变通道数,先加pw升维后,dw就能在高维提特征了。
- v2把原本dw之后用来降维的pw后的激活函数给去掉了。这么做据作者说是因为他认为非线性在高维有益处,但在低维(例如pw降维后的空间)不如线性好。
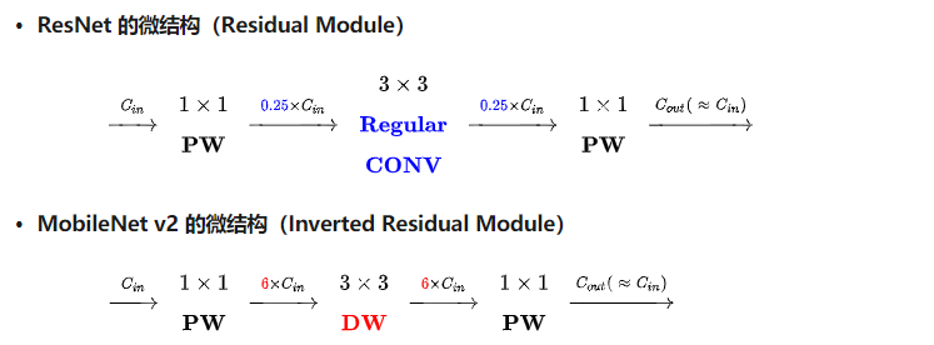
可以看到基本结构很相似。不过ResNet是先降维(0.25倍)、提特征、再升维。而v2则是先升维(6倍)、提特征、再降维。另外v2也用DW代替了标准卷积来做特征提取。