![]() CUDA provides a coding paradigm that extends languages like C, C++, Python, and Fortran, to be capable of running accelerated, massively parallelized code on the performant parallel processors: NVIDIA GPUs.
CUDA provides a coding paradigm that extends languages like C, C++, Python, and Fortran, to be capable of running accelerated, massively parallelized code on the performant parallel processors: NVIDIA GPUs.
CUDA accelerates applications drastically with little effort, has an ecosystem of highly optimized libraries for DNN, BLAS, graph analytics, FFT and more.
Accelerating Applications with CUDA C/C++
Objectives
- Call/Launch GPU kernels
- Control parallel thread hierarchy using execution configuration
- Refactor serial loops to execute their iterations in parallel on a GPU
- Allocate and free memory available to both CPUs and GPUs
- Handle errors generated by CUDA code
- Accelerate CPU-only applications
Accelerated System
Accelerated systems, also referred to as heterogeneous systems (异构系统), are those composed of both CPUs and GPUs.
Accelerated systems run CPU programs which in turn, launch functions that will benefit from the massive parallelism provided by GPUs.
Using Systems Management Interface cmd to check N-GPU environment:
!nvidia-smi
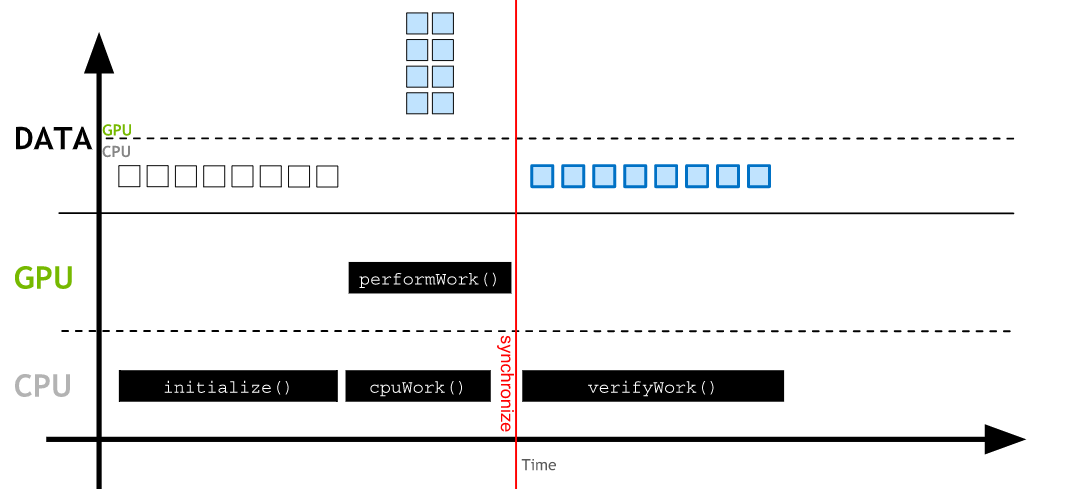
GPU-accelerated vs. CPU-only Applications:
In CPU-only applications data is allocated on CPU and all work is performed on CPU.
In accelerated applications data is allocated with cudaMallocManaged() where it can be accessed and worked on by the CPU and automatically migrated to the GPU where parallel work can be done.
Work on the GPU is asynchronous, and CPU can work at the same time. CPU code can sync with the asynchronous GPU work, waiting for it to complete with cudaDeviceSynchronize(). data accesses by the CPU will automatically be migrated.
Code for the GPU
.cu is the file extension for CUDA-accelerated programs.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void CPUFunction()
{
printf("run on the CPU.\n");
}
__global__ void GPUFunction()
{
printf("run on the GPU.\n");
}
int main()
{
CPUFunction();
GPUFunction<<<1, 1>>>();
cudaDeviceSynchronize();
}
__global__ void GPUFunction()
- The
__global__keyword indicates that the following function will run on the GPU, and can be invoked globally, which in this context means either by the CPU, or, by the GPU. - Often, code executed on the CPU is referred to as host code, and code running on the GPU is referred to as device code.
GPUFunction<<<1, 1>>>();
- Typically, when calling a function to run on the GPU, we call this function a kernel, which is launched.
- When launching a kernel, we must provide an execution configuration, which is done by using the
<<< ... >>>syntax just prior to passing the kernel any expected arguments. - At a high level, execution configuration allows programmers to specify the thread hierarchy for a kernel launch, which defines the number of thread groupings (called blocks), as well as how many threads to execute in each block. Execution configuration will be explored at great length later in the lab, but for the time being, notice the kernel is launching with
1block of threads (the first execution configuration argument) which contains1thread (the second configuration argument).
cudaDeviceSynchronize();
- Unlike much C/C++ code, launching kernels is asynchronous (异步): the CPU code will continue to execute without waiting for the kernel launch to complete.
- A call to
cudaDeviceSynchronize, a function provided by the CUDA runtime, will cause the host (CPU) code to wait until the device (GPU) code completes, and then resume execution on the CPU.
Compiling and Running Accelerated CUDA Code
The CUDA platform ships with the NVIDIA CUDA Compiler nvcc, which can compile CUDA accelerated applications, both the host, and the device code they contain.
nvcc will be very familiar to experienced gcc users. Compiling a some-CUDA.cu file:
nvcc -arch=sm_70 -o out some-CUDA.cu -run
- The
oflag is used to specify the output file for the compiled program. - The
archflag indicates for which architecture the files must be compiled. For the present casesm_70will serve to compile specifically for the Volta GPUs this lab is running on, but for those interested in a deeper dive, please refer to the docs about thearchflag, virtual architecture features and GPU features. - As a matter of convenience, providing the
runflag will execute the successfully compiled binary.
CUDA Thread Hierarchy
GPUs do work in parallel, and each GPU work is done in a thread. Many threads run in parallel.
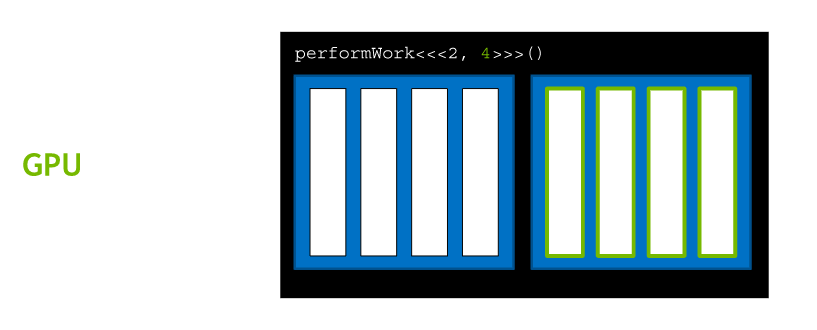 As mentioned above, GPU function is called kernel and Kernels are launched with an execution configuration.
As mentioned above, GPU function is called kernel and Kernels are launched with an execution configuration.
Launching Parallel Kernels
Execution configurations: <<< NUMBER_OF_BLOCKS, NUMBER_OF_THREADS_PER_BLOCK>>>
The kernel code is executed by every thread in every thread block configured when the kernel is launched.
CUDA-Provided Thread Hierarchy Variables
Just as threads are grouped into thread blocks, blocks are grouped into a grid, which is the highest entity in the CUDA thread hierarchy. In summary, CUDA kernels are executed in a grid of 1 or more blocks, with each block containing the same number of 1 or more threads.
Accelerating For Loops
For loops in CPU-only applications are ripe for acceleration: rather than run each iteration of the loop serially, each iteration of the loop can be run in parallel in its own thread.
Consider the following for loop:
1
2
3
4
5
int N = 2<<20;
for (int i = 0; i < N; ++i)
{
printf("%d\n", i);
}
In order to parallelize this loop, 2 steps must be taken:
- A kernel must be written to do the work of a single iteration of the loop.
- Because the kernel will be agnostic of other running kernels, the execution configuration must be such that the kernel executes the correct number of times, for example, the number of times the loop would have iterated.
1
2
3
4
__global__ void loop()
{
printf("This is iteration number %d\n", threadIdx.x);
}
Coordinating Parallel Threads (协调并行线程)
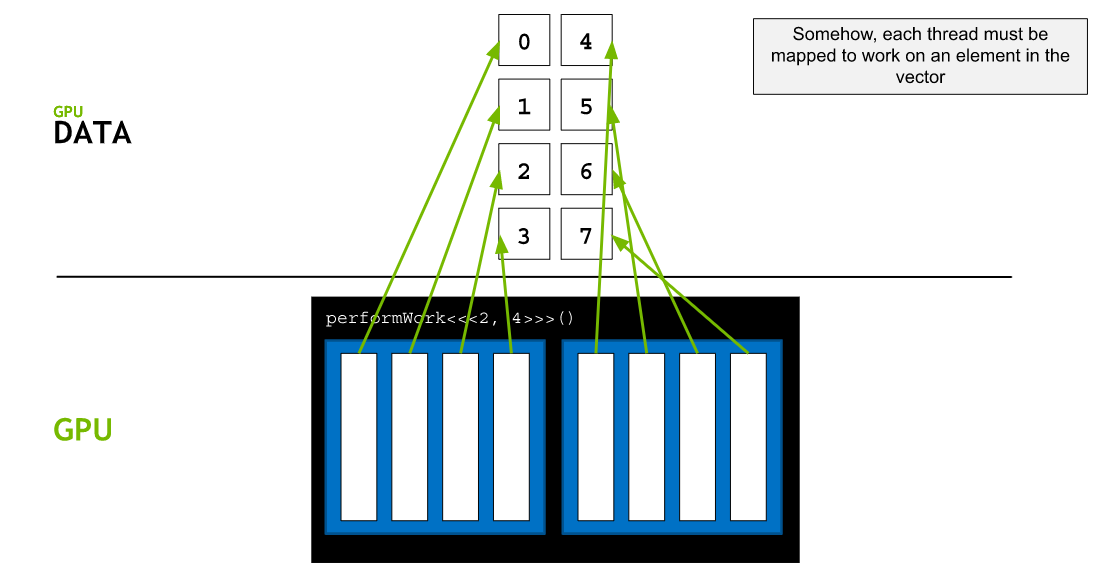
Assuming data is in a 0 indexed vector. Each thread must be mapped to work on an element in the vector.
Using the formula: threadIdx.x + blockIdx.x * blockDim.x will map each thread to one element in the vector.
Using Block Dimensions for More Parallelization
There is a limit to the number of threads that can exist in a thread block: 1024 to be precise. In order to increase the amount of parallelism in accelerated applications, we must be able to coordinate among multiple thread blocks.
Allocating Memory to be accessed on the GPU and the CPU
More recent versions of CUDA (version 6 and later) have made it easy to allocate memory that is available to both the CPU host and any number of GPU devices.
More reading: intermediate and advanced memory techniques
To allocate and free memory, and obtain a pointer that can be referenced in both host and device code, replace calls to malloc and free with cudaMallocManaged and cudaFree as in the following example:
1
2
3
4
5
6
7
8
9
// CPU-only
int N = 2<<20;
size_t size = N * sizeof(int);
int *a;
a = (int *)malloc(size);
// Use `a` in CPU-only program.
free(a);
1
2
3
4
5
6
7
8
9
10
// Accelerated
int N = 2<<20;
size_t size = N * sizeof(int);
int *a;
// Note the address of `a` is passed as first argument.
cudaMallocManaged(&a, size);
// Use `a` on the CPU and/or on any GPU in the accelerated system.
cudaFree(a);
Grid Size Work Amount Mismatch
What if there are more threads than work to be done? Access non-existent elements can reasult in a runtime error. (Code must check that the threadIdx.x + blockIdx.x * blockDim.x is less that N, the number of data elements)
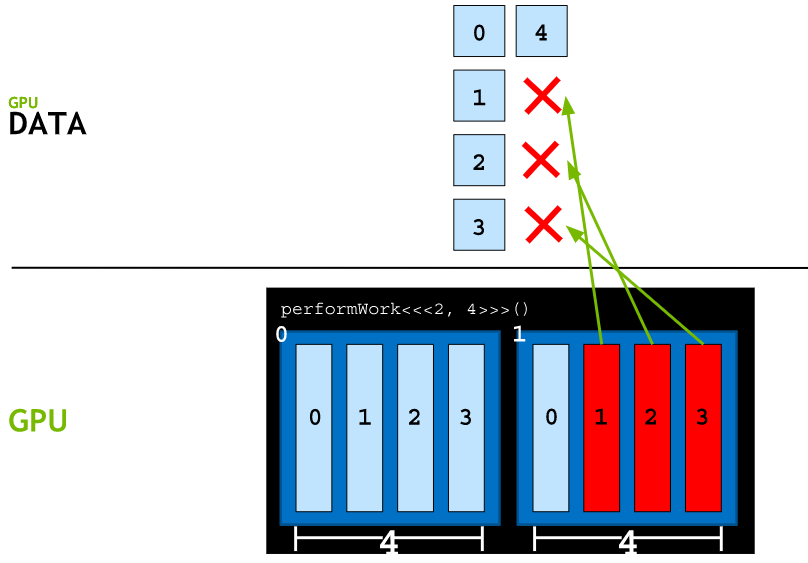
Handling Block Configuration Mismatches to Number of Needed Threads
An execution configuration cannot be expressed that will create the exact number of threads needed for parallelizing a loop.
This scenario can be easily addressed in the following way:
- Write an execution configuration that creates more threads than necessary to perform the allotted work.
- Pass a value as an argument into the kernel (
N) that represents to the total size of the data set to be processed, or the total threads that are needed to complete the work. - After calculating the thread’s index within the grid (using
tid+bid*bdim), check that this index does not exceedN, and only perform the pertinent work of the kernel if it does not.
Here is an example of an idiomatic way to write an execution configuration, and it ensures that there are always at least as many threads as needed for N, and only 1 additional block’s worth of threads extra, at most:
1
2
3
4
5
6
7
8
9
10
// Assume `N` is known
int N = 100000;
// Assume we have a desire to set `threads_per_block` exactly to `256`
size_t threads_per_block = 256;
// Ensure there are at least `N` threads in the grid, but only 1 block's worth extra
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
some_kernel<<<number_of_blocks, threads_per_block>>>(N);
Becuase the execution configuration above results in more threads in the grid than N, care will need to be taken inside of the some_kernel definition so that some_kernel does not attempt to access out of range data elements, when being executed by one of the “extra” threads:
1
2
3
4
5
6
7
8
9
__global__ some_kernel(int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) // Check to make sure `idx` maps to some value within `N`
{
// Only do work if it does
}
}
Grid-Stride Loops
Often there are more data elemens than there are threads in the grid. In this scenarios threads cannot work on only one element or else work is left undone. One way to address this programmatically is with a grid-stride loop.
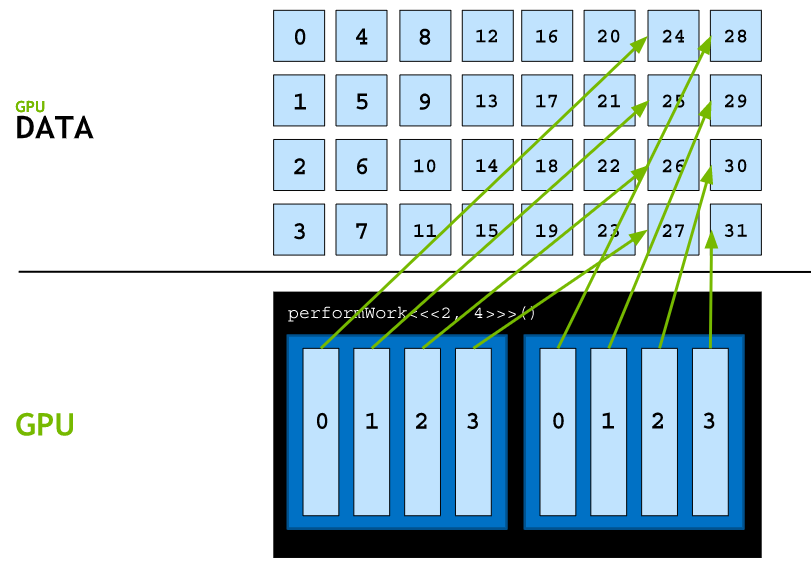 In a grid-stride loop, each thread will calculate its unique index within the grid using tid+bid*bdim, perform its operation on the element at that index within the array, and then, add to its index the number of threads in the grid and repeat, until it is out of range of the array.
In a grid-stride loop, each thread will calculate its unique index within the grid using tid+bid*bdim, perform its operation on the element at that index within the array, and then, add to its index the number of threads in the grid and repeat, until it is out of range of the array.
CUDA provides a special variable giving the number of blocks in a grid, gridDim.x. Calculating the total number of threads in a grid then is simply the number of blocks in a grid multiplied by the number of threads in each block, gridDim.x * blockDim.x. With this in mind, here is a verbose example of a grid-stride loop within a kernel:
1
2
3
4
5
6
7
8
9
10
__global void kernel(int *a, int N)
{
int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x;
for (int i = indexWithinTheGrid; i < N; i += gridStride)
{
// do work on a[i];
}
}
Error Handling
Many, if not most CUDA functions return a value of type cudaError_t, which can be used to check whether or not an error occured while calling the function. Here is an example where error handling is performed for a call to cudaMallocManaged:
1
2
3
4
5
6
7
cudaError_t err;
err = cudaMallocManaged(&a, N) // Assume the existence of `a` and `N`.
if (err != cudaSuccess) // `cudaSuccess` is provided by CUDA.
{
printf("Error: %s\n", cudaGetErrorString(err)); // `cudaGetErrorString` is provided by CUDA.
}
Launching kernels, which are defined to return void, do not return a value of type cudaError_t. To check for errors occuring at the time of a kernel launch, for example if the launch configuration is erroneous, CUDA provides the cudaGetLastError function, which does return a value of type cudaError_t.
1
2
3
4
5
6
7
8
9
10
11
12
13
/*
* This launch should cause an error, but the kernel itself
* cannot return it.
*/
someKernel<<<1, -1>>>(); // -1 is not a valid number of threads.
cudaError_t err;
err = cudaGetLastError(); // `cudaGetLastError` will return the error from above.
if (err != cudaSuccess)
{
printf("Error: %s\n", cudaGetErrorString(err));
}
Finally, in order to catch errors that occur asynchronously, for example during the execution of an asynchronous kernel, it is essential to check the status returned by a subsequent synchronizing cuda runtime API call, such as cudaDeviceSynchronize, which will return an error if one of the kernels launched previously should fail.
Wrapper CUDA function calls for checking errors:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
#include <assert.h>
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main()
{
/*
* The macro can be wrapped around any function returning
* a value of type `cudaError_t`.
*/
checkCuda( cudaDeviceSynchronize() )
}
Grids and Blocks of 2 and 3 Dimensions
Grids and blocks can be defined to have up to 3 dimensions. Defining them with multiple dimensions does not impact their performance in any way, but can be very helpful when dealing with data that has multiple dimensions, for example, 2d matrices. To define either grids or blocks with two or 3 dimensions, use CUDA’s dim3 type as such:
1
2
3
dim3 threads_per_block(16, 16, 1);
dim3 number_of_blocks(16, 16, 1);
someKernel<<<number_of_blocks, threads_per_block>>>();
Given the example just above, the variables gridDim.x, gridDim.y, blockDim.x, and blockDim.y inside of someKernel, would all be equal to 16.
Project 1: Accelerate Vector Addition Application
This project contains a functioning CPU-only vector addition application. Accelerate its addVectorsInto function to run as a CUDA kernel on the GPU and to do its work in parallel.
- Augment the
addVectorsIntodefinition so that it is a CUDA kernel. - Choose and utilize a working execution configuration so that
addVectorsIntolaunches as a CUDA kernel. - Update memory allocations, and memory freeing to reflect that the 3 vectors
a,b, andresultneed to be accessed by host and device code. - Refactor the body of
addVectorsInto: it will be launched inside of a single thread, and only needs to do one thread’s worth of work on the input vectors. Be certain the thread will never try to access elements outside the range of the input vectors, and take care to note whether or not the thread needs to do work on more than one element of the input vectors. - Add error handling in locations where CUDA code might otherwise silently fail.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
#include <stdio.h>
#include <assert.h>
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__ void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *array, int N)
{
for(int i = 0; i < N; i++)
{
if(array[i] != target)
{
printf("FAIL: array[%d] - %0.0f does not equal %0.0f\n", i, array[i], target);
exit(1);
}
}
printf("SUCCESS! All values added correctly.\n");
}
int main()
{
const int N = 2<<20;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
//a = (float *)malloc(size);
//b = (float *)malloc(size);
//c = (float *)malloc(size);
checkCuda( cudaMallocManaged(&a, size) );
checkCuda( cudaMallocManaged(&b, size) );
checkCuda( cudaMallocManaged(&c, size) );
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
checkCuda( cudaGetLastError() );
checkCuda( cudaDeviceSynchronize() );
checkElementsAre(7, c, N);
checkCuda( cudaFree(a) );
checkCuda( cudaFree(b) );
checkCuda( cudaFree(c) );
}
Project 2: Accelerate 2D Matrix Multiply Application
The task is to build out the matrixMulGPU CUDA kernel.
- It will need to create an execution configuration whose arguments are both
dim3values with thexandydimensions set to greater than1. - Inside the body of the kernel, it will need to establish the running thread’s unique index within the grid per usual, but it should establish two indices for the thread: one for the x axis of the grid, and one for the y axis of the grid.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
#include <stdio.h>
#define N 64
__global__ void matrixMulGPU( int * a, int * b, int * c )
{
int val = 0;
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if (row < N && col < N) // replaced "for" loops
{
for ( int k = 0; k < N; ++k )
{
val += a[row * N + k] * b[k * N + col];
}
c[row * N + col] = val;
}
}
/*
* This CPU function already works, and will run to create a solution matrix
* against which to verify your work building out the matrixMulGPU kernel.
*/
void matrixMulCPU( int * a, int * b, int * c )
{
int val = 0;
for( int row = 0; row < N; ++row )
{
for( int col = 0; col < N; ++col )
{
val = 0;
for ( int k = 0; k < N; ++k )
{
val += a[row * N + k] * b[k * N + col];
}
c[row * N + col] = val;
}
}
}
int main()
{
int *a, *b, *c_cpu, *c_gpu; // Allocate a solution matrix for both the CPU and the GPU operations
int size = N * N * sizeof (int); // Number of bytes of an N x N matrix
// Allocate memory
cudaMallocManaged (&a, size);
cudaMallocManaged (&b, size);
cudaMallocManaged (&c_cpu, size);
cudaMallocManaged (&c_gpu, size);
// Initialize memory; create 2D matrices
for( int row = 0; row < N; ++row )
for( int col = 0; col < N; ++col )
{
a[row*N + col] = row;
b[row*N + col] = col+2;
c_cpu[row*N + col] = 0;
c_gpu[row*N + col] = 0;
}
/*
* Assign `threads_per_block` and `number_of_blocks` 2D values
* that can be used in matrixMulGPU above.
*/
dim3 threads_per_block (16, 16, 1); // A 16 x 16 block threads
dim3 number_of_blocks ((N / threads_per_block.x) + 1, (N / threads_per_block.y) + 1, 1);
matrixMulGPU <<< number_of_blocks, threads_per_block >>> ( a, b, c_gpu );
cudaDeviceSynchronize();
// Call the CPU version to check our work
matrixMulCPU( a, b, c_cpu );
// Compare the two answers to make sure they are equal
bool error = false;
for( int row = 0; row < N && !error; ++row )
{
for( int col = 0; col < N && !error; ++col )
{
if (c_cpu[row * N + col] != c_gpu[row * N + col])
{
printf("FOUND ERROR at c[%d][%d]\n", row, col);
error = true;
break;
}
}
}
if (!error)
{
printf("Success!\n");
}
// Free all our allocated memory
cudaFree(a);
cudaFree(b);
cudaFree( c_cpu );
cudaFree( c_gpu );
}
Project 3: Accelerate A Thermal Conductivity Application
Convert the step_kernel_mod function to execute on the GPU, and modify the main function to properly allocate data for use on CPU and GPU. The step_kernel_ref function executes on the CPU and is used for error checking. Because this code involves floating point calculations, different processors, or even simply reording operations on the same processor, can result in slightly different results. For this reason the error checking code uses an error threshold, instead of looking for an exact match.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
#include <stdio.h>
#include <math.h>
// Simple define to index into a 1D array from 2D space
#define I2D(num, c, r) ((r)*(num)+(c))
/*
* `step_kernel_mod` is currently a direct copy of the CPU reference solution
* `step_kernel_ref` below. Accelerate it to run as a CUDA kernel.
*/
/*
void step_kernel_mod(int ni, int nj, float fact, float* temp_in, float* temp_out)
{
int i00, im10, ip10, i0m1, i0p1;
float d2tdx2, d2tdy2;
// loop over all points in domain (except boundary)
for ( int j=1; j < nj-1; j++ ) {
for ( int i=1; i < ni-1; i++ ) {
// find indices into linear memory
// for central point and neighbours
i00 = I2D(ni, i, j);
im10 = I2D(ni, i-1, j);
ip10 = I2D(ni, i+1, j);
i0m1 = I2D(ni, i, j-1);
i0p1 = I2D(ni, i, j+1);
// evaluate derivatives
d2tdx2 = temp_in[im10]-2*temp_in[i00]+temp_in[ip10];
d2tdy2 = temp_in[i0m1]-2*temp_in[i00]+temp_in[i0p1];
// update temperatures
temp_out[i00] = temp_in[i00]+fact*(d2tdx2 + d2tdy2);
}
}
}
*/
__global__ void step_kernel_mod(int ni, int nj, float fact, float* temp_in, float* temp_out)
{
int i00, im10, ip10, i0m1, i0p1;
float d2tdx2, d2tdy2;
int j = blockIdx.x * blockDim.x + threadIdx.x;
int i = blockIdx.y * blockDim.y + threadIdx.y;
// loop over all points in domain (except boundary)
if (j > 0 && i > 0 && j < nj-1 && i < ni-1)
{
// find indices into linear memory
// for central point and neighbours
i00 = I2D(ni, i, j);
im10 = I2D(ni, i-1, j);
ip10 = I2D(ni, i+1, j);
i0m1 = I2D(ni, i, j-1);
i0p1 = I2D(ni, i, j+1);
// evaluate derivatives
d2tdx2 = temp_in[im10]-2*temp_in[i00]+temp_in[ip10];
d2tdy2 = temp_in[i0m1]-2*temp_in[i00]+temp_in[i0p1];
// update temperatures
temp_out[i00] = temp_in[i00]+fact*(d2tdx2 + d2tdy2);
}
}
void step_kernel_ref(int ni, int nj, float fact, float* temp_in, float* temp_out)
{
int i00, im10, ip10, i0m1, i0p1;
float d2tdx2, d2tdy2;
// loop over all points in domain (except boundary)
for ( int j=1; j < nj-1; j++ ) {
for ( int i=1; i < ni-1; i++ ) {
// find indices into linear memory
// for central point and neighbours
i00 = I2D(ni, i, j);
im10 = I2D(ni, i-1, j);
ip10 = I2D(ni, i+1, j);
i0m1 = I2D(ni, i, j-1);
i0p1 = I2D(ni, i, j+1);
// evaluate derivatives
d2tdx2 = temp_in[im10]-2*temp_in[i00]+temp_in[ip10];
d2tdy2 = temp_in[i0m1]-2*temp_in[i00]+temp_in[i0p1];
// update temperatures
temp_out[i00] = temp_in[i00]+fact*(d2tdx2 + d2tdy2);
}
}
}
int main()
{
int istep;
int nstep = 200; // number of time steps
// Specify our 2D dimensions
const int ni = 200;
const int nj = 100;
float tfac = 8.418e-5; // thermal diffusivity of silver
float *temp1_ref, *temp2_ref, *temp1, *temp2, *temp_tmp;
const int size = ni * nj * sizeof(float);
temp1_ref = (float*)malloc(size);
temp2_ref = (float*)malloc(size);
//temp1 = (float*)malloc(size);
//temp2 = (float*)malloc(size);
cudaMallocManaged(&temp1, size);
cudaMallocManaged(&temp2, size);
// Initialize with random data
for( int i = 0; i < ni*nj; ++i) {
temp1_ref[i] = temp2_ref[i] = temp1[i] = temp2[i] = (float)rand()/(float)(RAND_MAX/100.0f);
}
// Execute the CPU-only reference version
for (istep=0; istep < nstep; istep++) {
step_kernel_ref(ni, nj, tfac, temp1_ref, temp2_ref);
// swap the temperature pointers
temp_tmp = temp1_ref;
temp1_ref = temp2_ref;
temp2_ref= temp_tmp;
}
dim3 tblocks(32, 16, 1);
dim3 grid((nj/tblocks.x)+1, (ni/tblocks.y)+1, 1);
cudaError_t ierrSync, ierrAsync;
// Execute the modified version using same data
//for (istep=0; istep < nstep; istep++) {
//step_kernel_mod(ni, nj, tfac, temp1, temp2);
for (istep=0; istep < nstep; istep++)
{
step_kernel_mod<<< grid, tblocks >>>(ni, nj, tfac, temp1, temp2);
ierrSync = cudaGetLastError();
ierrAsync = cudaDeviceSynchronize(); // Wait for the GPU to finish
if (ierrSync != cudaSuccess)
{ printf("Sync error: %s\n", cudaGetErrorString(ierrSync)); }
if (ierrAsync != cudaSuccess)
{ printf("Async error: %s\n", cudaGetErrorString(ierrAsync)); }
// swap the temperature pointers
temp_tmp = temp1;
temp1 = temp2;
temp2= temp_tmp;
}
float maxError = 0;
// Output should always be stored in the temp1 and temp1_ref at this point
for( int i = 0; i < ni*nj; ++i ) {
if (abs(temp1[i]-temp1_ref[i]) > maxError) { maxError = abs(temp1[i]-temp1_ref[i]); }
}
// Check and see if our maxError is greater than an error bound
if (maxError > 0.0005f)
printf("Problem! The Max Error of %.5f is NOT within acceptable bounds.\n", maxError);
else
printf("The Max Error of %.5f is within acceptable bounds.\n", maxError);
free( temp1_ref );
free( temp2_ref );
cudaFree( temp1 );
cudaFree( temp2 );
return 0;
}