![]() The CUDA tookit ships with the Nsight Systems, a powerful GUI application to support the development of accelerated CUDA applications. Nsight Systems generates a graphical timeline of an accelerated application, with detailed information about CUDA API calls, kernel execution, memory activity, and the use of CUDA streams.
The CUDA tookit ships with the Nsight Systems, a powerful GUI application to support the development of accelerated CUDA applications. Nsight Systems generates a graphical timeline of an accelerated application, with detailed information about CUDA API calls, kernel execution, memory activity, and the use of CUDA streams.
In this lab, it will be using the Nsight Systems timeline to guide in optimizing accelerated applications. Additionally, it will cover some intermediate CUDA programming techniques to support your work: unmanaged memory allocation and migration; pinning, or page-locking host memory; and non-default concurrent CUDA streams.
Objectives
- Use Nsight Systems to visually profile the timeline of GPU-accelerated CUDA applications.
- Use Nsight Systems to identify, and exploit, optimization opportunities in GPU-accelerated CUDA applications.
- Utilize CUDA streams for concurrent(并发) kernel execution in accelerated applications.
- (Optional Advanced Content) Use manual device memory allocation, including allocating pinned memory, in order to asynchronously transfer data in concurrent CUDA streams.
Running Nsight Systems
1. Generate Report File
Compile and run the code. Next, use nsys profile --stats=true to create a report file that I will be able to open in the Nsight Systems visual profiler.
And using the -o flag to give the report file a memorable name.
2. Open Nsight System
To open Nsight Systems, enter and run the nsight-sys command from a open terminal.
3. Enable Usage Reporting
When prompted, click “Yes” to enable usage collection.
4. Open the Report File
Open the targeting report file by visiting File -> Open from the Nsight Systems menu, then go to the path /root/Desktop/directory/... and select filename.qdrep.
5. Expand the CUDA Unified Memory Timelines
Next, expand the CUDA -> Unified memory and Context timelines, and close the OS runtime libraries timelines
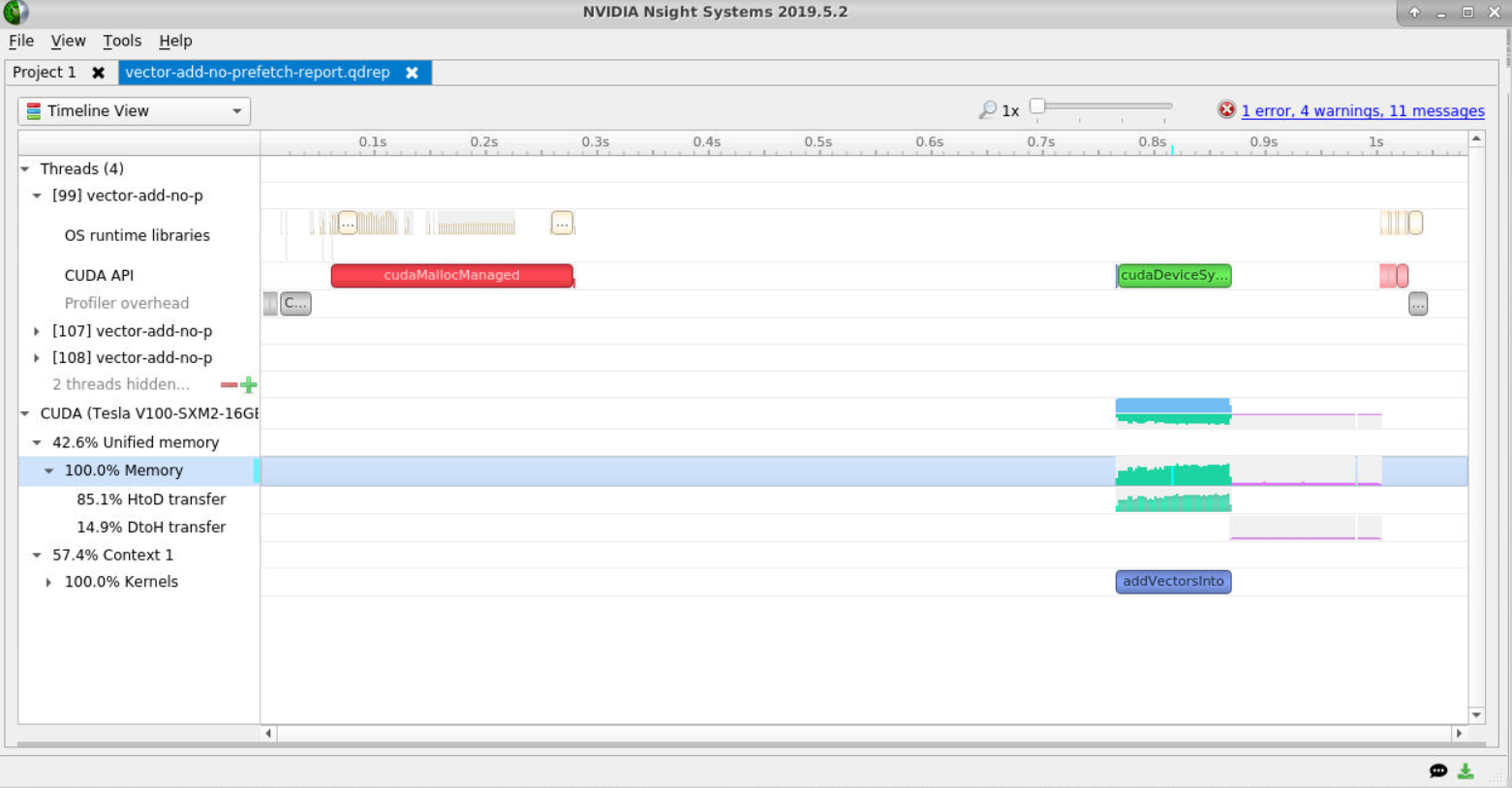
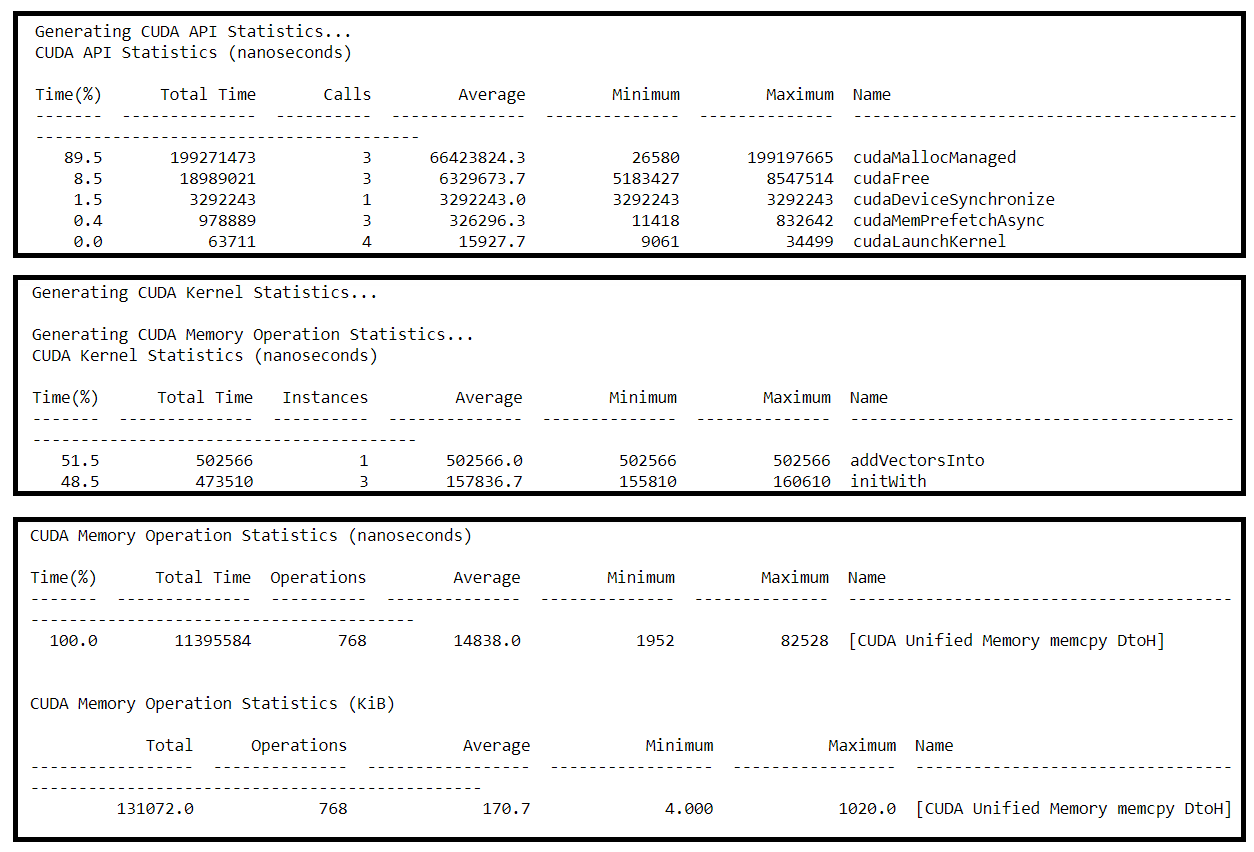
6. Observe Many Memory Transfers
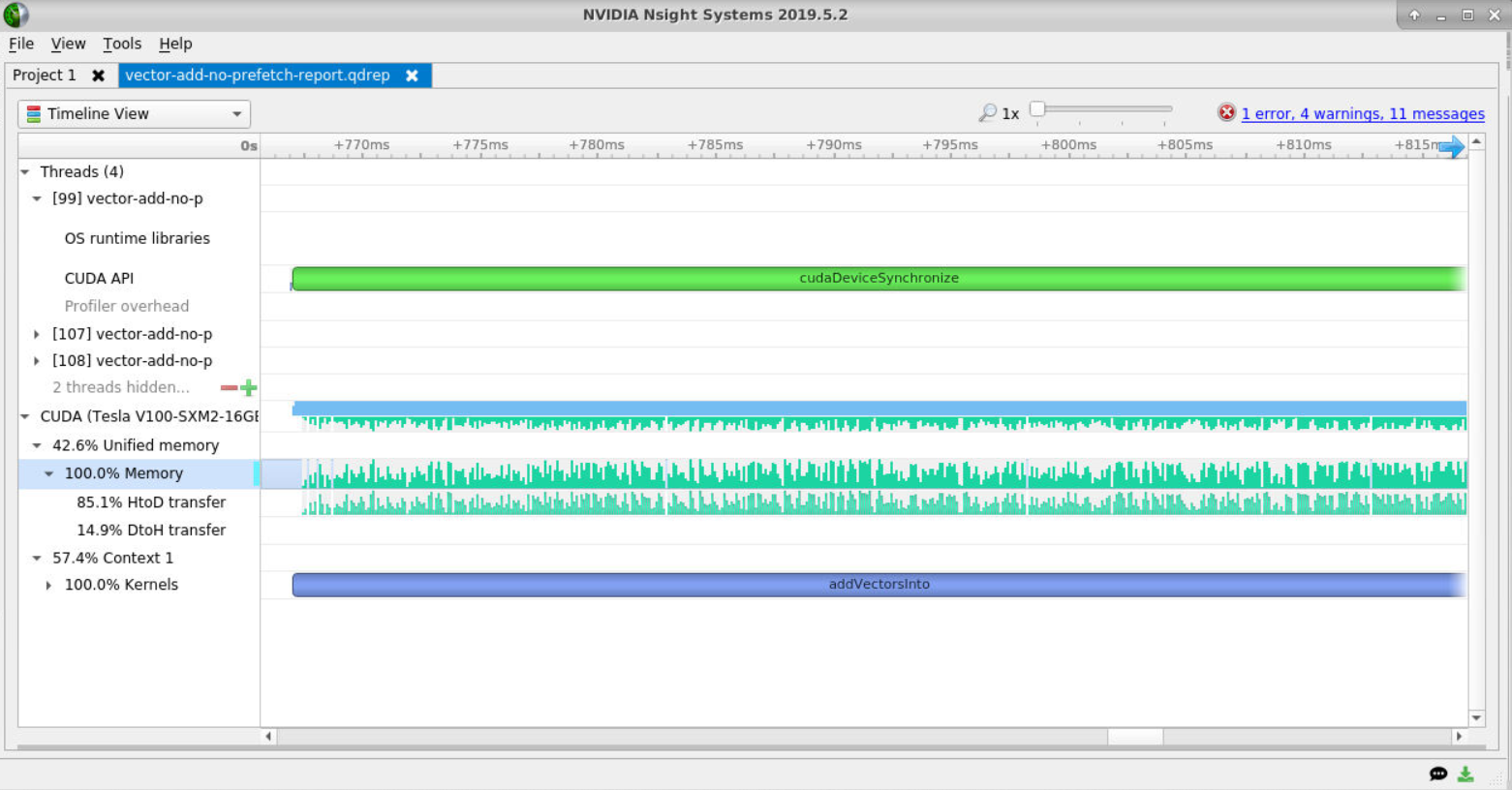
From a glance it can see the application is taking about 1 second to run, and that also, during the time when the addVectorsInto kernel is running, that there is a lot of UM memory activity (above picture).
Zoom into the memory timelines to see more clearly all the small memory transfers being caused by the on-demand memory page faults.
Code Refactor
Baseline code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
#include <stdio.h>
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
And its Nsys profile:
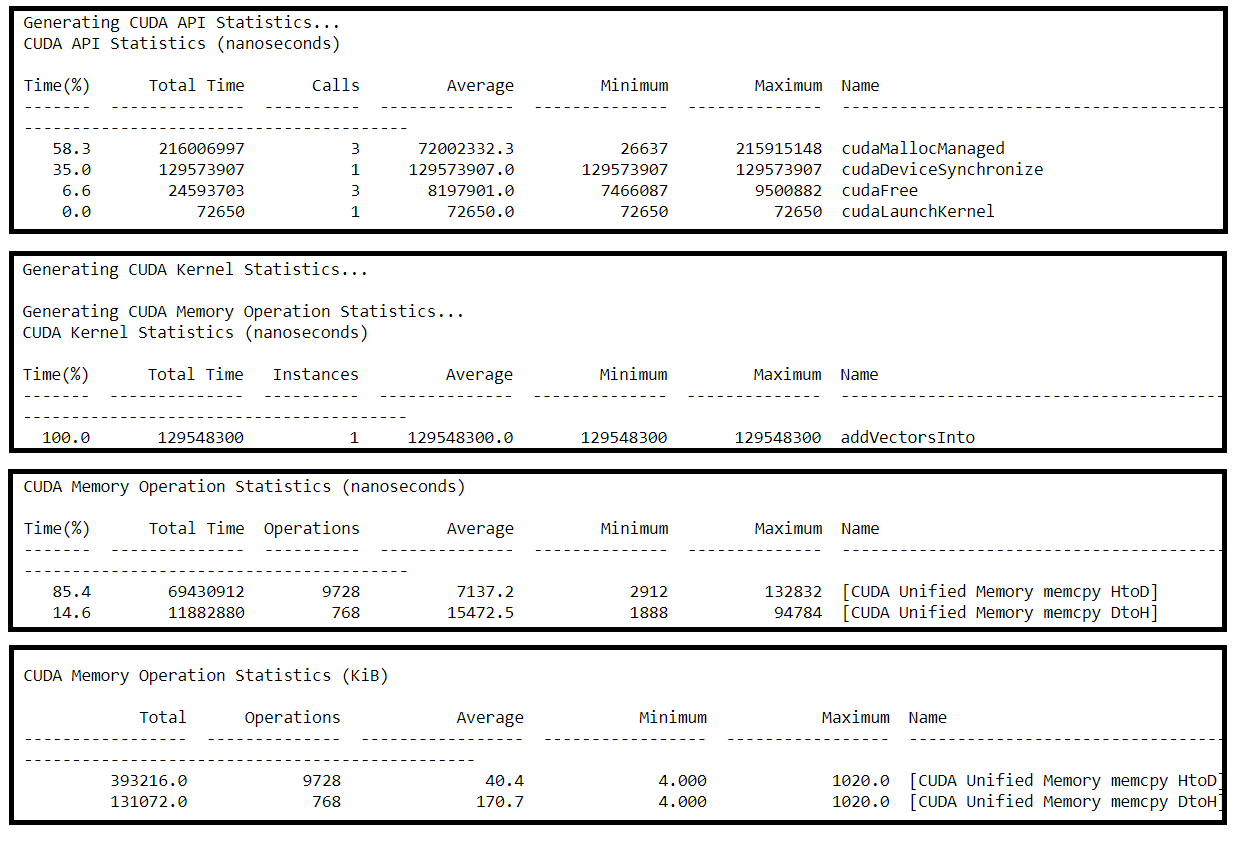
Prefetching vs. Non-Prefetching
This version refactors the vector addition application from above so that the 3 vectors needed by its addVectorsInto kernel are asynchronously prefetched to the active GPU device prior to launching the kernel (using cudaMemPrefetchAsync).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
#include <stdio.h>
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
And its Nsys profile:
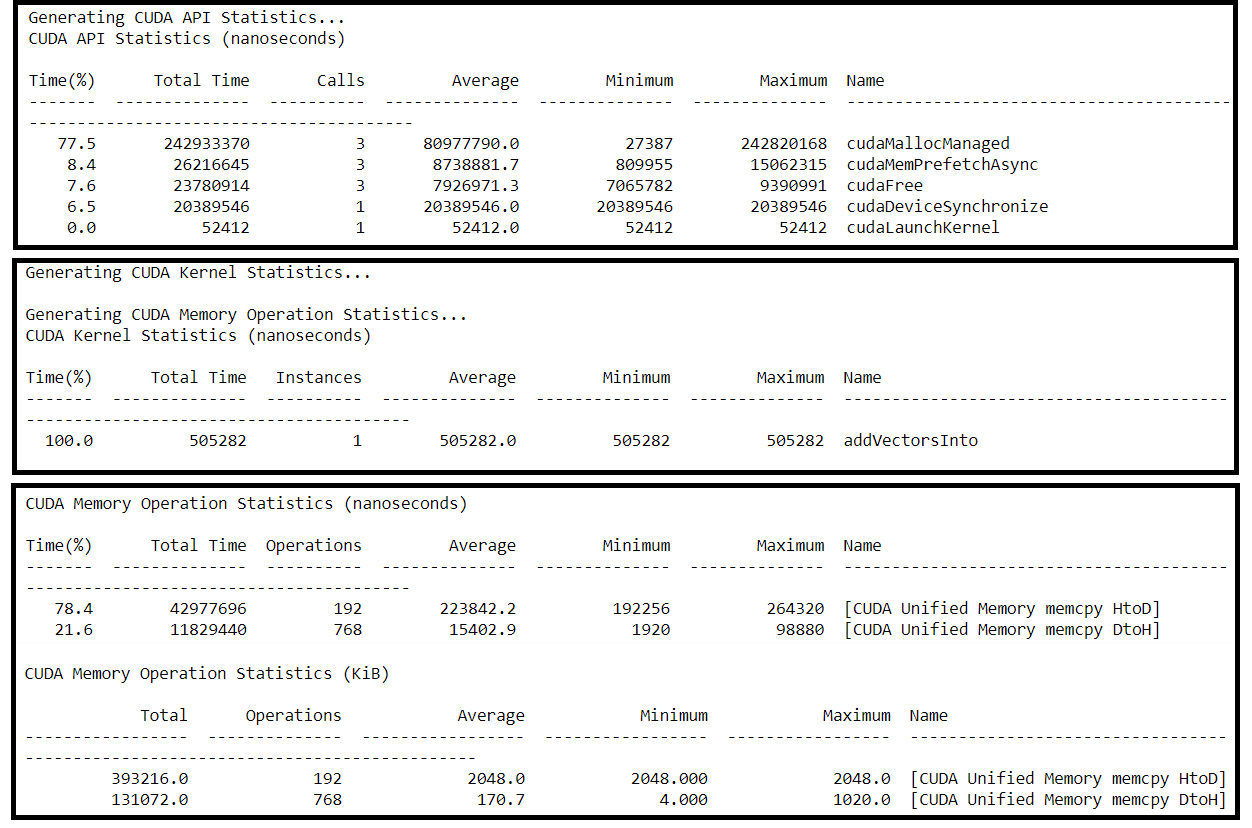 For comparison:
For comparison:
- How does the execution time compare to that of the
addVectorsIntokernel prior to adding asynchronous prefetching?Execution time dramatically dropped after adding asynchronous prefetching.
- How have the memory transfers changed?
Less operations happened so less time on HtoD, and more data migrate from Host to Device each operation.
Launch Init in Kernel
In the previous iteration of the vector addition application, the vector data is being initialized on the CPU, and therefore needs to be migrated to the GPU before the addVectorsInto kernel can operate on it.
Next, the application will be refactored to initialize the data in parallel on the GPU.
Since the initialization now takes place on the GPU, prefetching has been done prior to initialization, rather than prior to the vector addition work.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
And its Nsys profile:
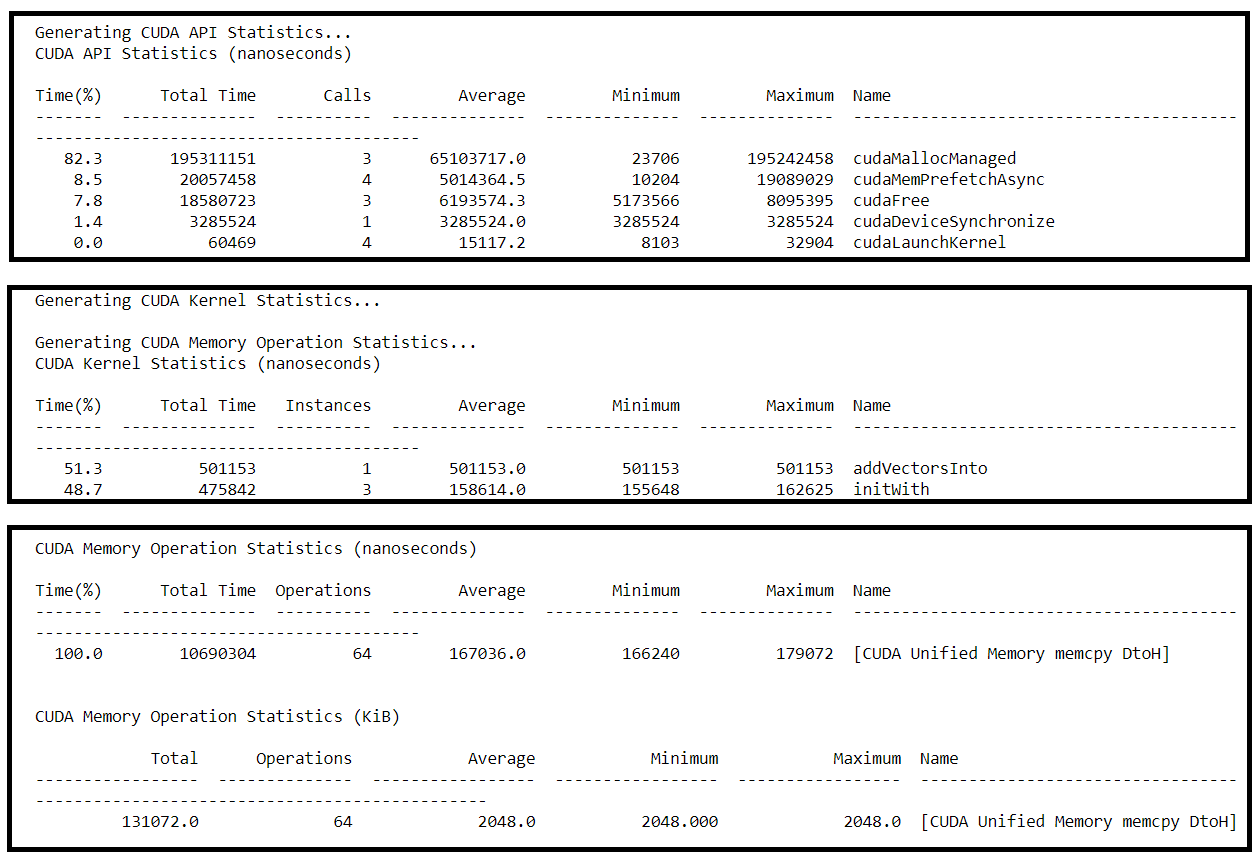
 For comparison:
For comparison:
- Compare the application and
addVectorsIntoruntimes to the previous version of the application, how did they change?there is
initWithruntime occurs, butaddVectorsIntotook the same runtime as previous. - Which of the following does your application contain? 1. HtoD; 2. DtoH
Only DtoH remained.
Asynchronous Prefetch Back to the Host
Currently, the vector addition application verifies the work of the vector addition kernel on the host.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId); //Asynchronous Prefetch Back to the Host
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
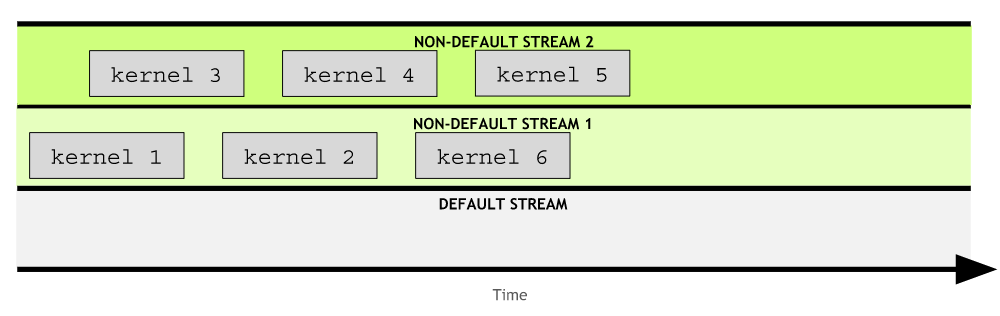
Concurrent CUDA Streams
A stream is a series of instructions, and CUDA has a default stream. In any stram, including the default, an instruction in it must complete before the next can begin.
Non-default streams can also be created for kernel execution. Kernels within any single stream must execute in order. However, kernels in different, non-defaults streams, can interact concurrently.
 The default stream is special: it blocks all kernels in all other streams.
The default stream is special: it blocks all kernels in all other streams.
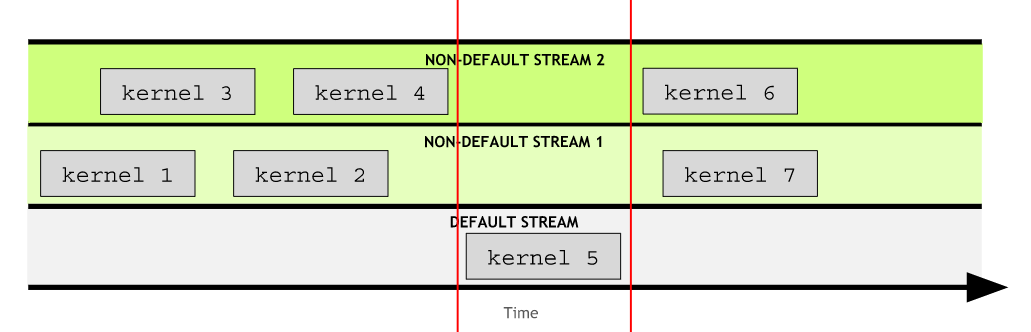 CUDA programmers can create and utilize non-default CUDA streams in addition to the default stream, and in doing so, perform multiple operations, such as executing multiple kernels, concurrently, in different streams.
CUDA programmers can create and utilize non-default CUDA streams in addition to the default stream, and in doing so, perform multiple operations, such as executing multiple kernels, concurrently, in different streams.
Rules Governing the Behavior of CUDA Streams
There are a few rules, concerning the behavior of CUDA streams, that should be learned in order to utilize them effectively:
- Operations within a given stream occur in order.
- Operations in different non-default streams are not guaranteed to operate in any specific order relative to each other.
- The default stream is blocking and will both wait for all other streams to complete before running, and, will block other streams from running until it completes.
Creating, Utilizing, and Destroying Non-Default CUDA Streams
The following code snippet demonstrates how to create, utilize, and destroy a non-default CUDA stream. To launch a CUDA kernel in a non-default CUDA stream, the stream must be passed as the optional 4th argument of the execution configuration. Up until now we have only utilized the first 2 arguments of the execution configuration:
1
2
3
4
5
6
cudaStream_t stream; // CUDA streams are of type `cudaStream_t`.
cudaStreamCreate(&stream); // Note that a pointer must be passed to `cudaCreateStream`.
someKernel<<<number_of_blocks, threads_per_block, 0, stream>>>(); // `stream` is passed as 4th EC argument.
cudaStreamDestroy(stream); // Note that a value, not a pointer, is passed to `cudaDestroyStream`.
Outside the scope of this lab, but worth mentioning, is the optional 3rd argument of the execution configuration. This argument allows programmers to supply the number of bytes in shared memory to be dynamically allocated per block for this kernel launch. The default number of bytes allocated to shared memory per block is 0, and for the remainder of the lab, it will be passing 0 as this value, in order to expose the 4th argument.
Code baseline:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <stdio.h>
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
printNumber<<<1, 1>>>(i);
}
cudaDeviceSynchronize();
}
Implement Concurrent CUDA Streams
Each kernel launch occurs in its own non-default stream:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <stdio.h>
#include <unistd.h>
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
cudaStream_t stream;
cudaStreamCreate(&stream);
printNumber<<<1, 1, 0, stream>>>(i);
cudaStreamDestroy(stream);
}
cudaDeviceSynchronize();
}
Use Streams for Concurrent Data Initialization Kernels
The vector addition application you have been working with, currently launches an initialization kernel 3 times - once each for each of the 3 vectors needing initialization for the vectorAdd kernel. Refactor it to launch each of the 3 initialization kernel launches in their own non-default stream.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
// Create 3 streams to run initialize the 3 data vectors in parallel.
cudaStream_t stream1, stream2, stream3;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
// Give each `initWith` launch its own non-standard stream.
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream1>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream2>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream3>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
// Destroy streams when they are no longer needed
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaStreamDestroy(stream3);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
At this point in time we have a wealth of fundamental tools and techniques for accelerating CPU-only applications, and for then optimizing those accelerated applications.
Final Exercise: Accelerate and Optimize an N-Body Simulator
An n-body simulator predicts the individual motions of a group of objects interacting with each other gravitationally. nbody.cu contains a simple, though working, n-body simulator for bodies moving through 3 dimensional space. The application can be passed a command line argument to affect how many bodies are in the system.
In its current CPU-only form, working on 4096 bodies, this application is able to calculate about 30 million interactions between bodies in the system per second. The task is to:
- GPU accelerate the program, retaining the correctness of the simulation
- Work iteratively to optimize the simulator so that it calculates over 30 billion interactions per second while working on 4096 bodies
(2<<11) - Work iteratively to optimize the simulator so that it calculates over 325 billion interactions per second while working on ~65,000 bodies
(2<<15)
Path for problem solving:
- Refactor
bodyForceinto a kernel function so that it could run on GPU. Multi epoch must executedin order, so the Concurrent stream could not be used. The default stream could do the job; - Refactor the for-loop after
bodyForceinto kernel function; - Refactor with block size and multi-threading.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
#include "check.h"
#define SOFTENING 1e-9f
// Each body contains x, y, and z coordinate positions, as well as velocities in the x, y, and z directions.
typedef struct { float x, y, z, vx, vy, vz; } Body;
// Do not modify this function. A constraint of this exercise is that it remain a host function.
void randomizeBodies(float *data, int n) {
for (int i = 0; i < n; i++) {
data[i] = 2.0f * (rand() / (float)RAND_MAX) - 1.0f;
}
}
// This function calculates the gravitational impact of all bodies in the system on all others, but does not update their positions.
__global__
void bodyForce(Body *p, float dt, int n)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
float Fx = 0.0f; float Fy = 0.0f; float Fz = 0.0f;
for (int j = 0; j < n; j++)
{
float dx = p[j].x - p[i].x;
float dy = p[j].y - p[i].y;
float dz = p[j].z - p[i].z;
float distSqr = dx*dx + dy*dy + dz*dz + SOFTENING;
float invDist = rsqrtf(distSqr);
float invDist3 = invDist * invDist * invDist;
Fx += dx * invDist3;
Fy += dy * invDist3;
Fz += dz * invDist3;
}
p[i].vx += dt*Fx;
p[i].vy += dt*Fy;
p[i].vz += dt*Fz;
}
}
__global__
void add(Body*p, float dt,int n)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
p[i].x += p[i].vx*dt;
p[i].y += p[i].vy*dt;
p[i].z += p[i].vz*dt;
}
}
int main(const int argc, const char** argv) {
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
// Do not change the value for `nBodies` here. If you would like to modify it, pass values into the command line.
int nBodies = 2<<11;
int salt = 0;
if (argc > 1) nBodies = 2<<atoi(argv[1]);
// This salt is for assessment reasons. Tampering with it will result in automatic failure.
if (argc > 2) salt = atoi(argv[2]);
const float dt = 0.01f; // time step
const int nIters = 10; // simulation iterations
int bytes = nBodies * sizeof(Body);
float *buf;
cudaMallocManaged(&buf, bytes);
//cudaMemPrefetchAsync(buf, bytes, deviceId);
Body *p = (Body*)buf;
// As a constraint of this exercise, `randomizeBodies` must remain a host function.
randomizeBodies(buf, 6 * nBodies); // Init pos / vel data
size_t threadsPerBlock = 256;
size_t numberOfBlocks = 32 * numberOfSMs;
double totalTime = 0.0;
//This simulation will run for 10 cycles of time, calculating gravitational interaction amongst bodies, and adjusting their positions to reflect.
for (int iter = 0; iter < nIters; iter++)
{
StartTimer();
// It will likely wish to refactor the work being done in `bodyForce`, as well as the work to integrate the positions.
bodyForce<<< numberOfBlocks, threadsPerBlock >>>(p, dt, nBodies); // compute interbody forces
cudaDeviceSynchronize();
add<<< numberOfBlocks, threadsPerBlock >>>(p, dt, nBodies);
const double tElapsed = GetTimer() / 1000.0;
totalTime += tElapsed;
}
cudaDeviceSynchronize();
double avgTime = totalTime / (double)(nIters);
float billionsOfOpsPerSecond = 1e-9 * nBodies * nBodies / avgTime;
#ifdef ASSESS
checkPerformance(buf, billionsOfOpsPerSecond, salt);
#else
checkAccuracy(buf, nBodies);
printf("%d Bodies: average %0.3f Billion Interactions / second\n", nBodies, billionsOfOpsPerSecond);
salt += 1;
#endif
cudaFree(buf);
}