This blog is the notbook for OCR fundamental studies, which will include: 1. Graphic Text Recognition: Tesseract, Keras-OCR 2. Text Detection: EAST, CRAFT
Realistic scenario: text in imagery
1. Graphic text (scanned documents…)
2. Scene text (clothing, signs, packages…)
OCR pipeline
- Two-Step:
a. text detection module that detects and ocalizes the existence of text;
b. text recognition module that transcribes and converts the content of the detected text region into linguistic symbols. - End-to-End:
single module with detection & recognition.
Tesseract pipeline
Tesseract -> text recognition (OCR) engine -> extract text from images.
1. Adaptive Thresholding
2. Page Layout Analysis: document -> segments
a. connected component analysis, to get Blobs;
b. from Blobs to get fixed-pitch/proportional texts.
3. Word Recognize: Pass 1 & 2 (to gain high confidence)
4. Fix: X-Height, Fuzzy Space, Word Bigram
5. Output Text
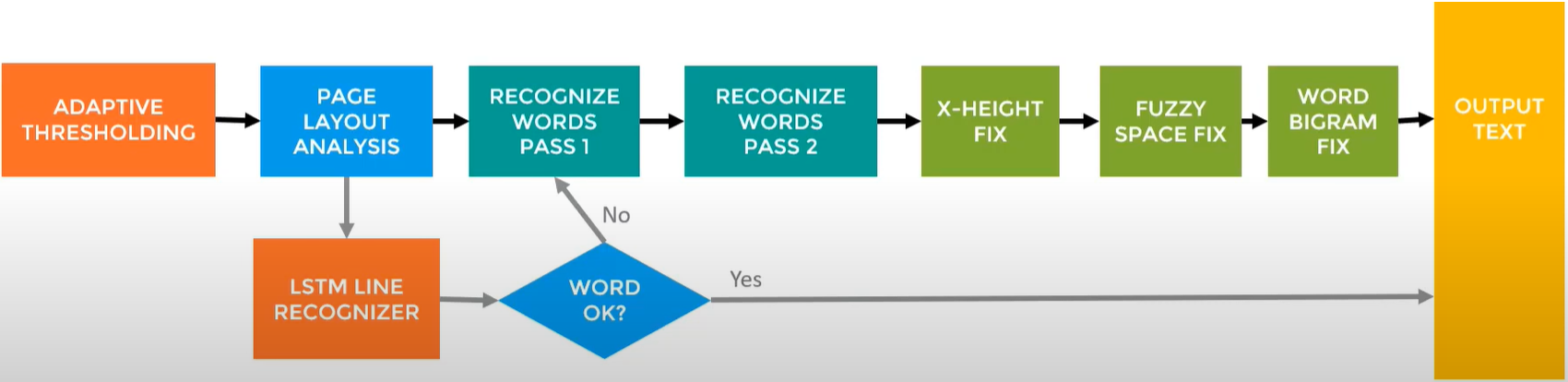
Tesseract is not always a pipeline, but a circle between 2 -> 4 -> 3 -> 5, or 4 -> 3 -> 5.
Tesseract Experiments
1. Install Tesseract Library:
!apt install libtesseract-dev tesseract-ocr > /dev/null
2. Install Python wrapper for Tesseract:
!pip install pytesseract > /dev/null
3. Perform OCR:
1
2
import pytesseract
text = pytesseract.image_to_string('text.jpg')
From experiments, even though it is natural image, Tesseract is able to perform OCR almost without any errors, but it will be surprised by how fast the output deteriorates on small changes in the images. Major reasons for failure of OCR using Tesseract and in general. They are:
- Cluttered Background: The text might not be visibly clear or it might appear camouflaged with the background.
- Small Text: The text might be too small to be detected.
- Rotation or Perspective Distortion: The text might be rotated in the image or the image itself might be distorted.
Tesseract Functions
get_tesseract_version- Returns the Tesseract version installed in the system.image_to_string- Returns the result of a Tesseract OCR run on the image as a single stringimage_to_boxes- Returns the recognized characters and their box boundaries.image_to_data- Returns the box boundaries/locations, confidences, words etc.image_to_osd- Returns result containing information about orientation and script detection.image_to_pdf_or_hocr- Returns a searchable PDF from the input image.run_and_get_output- Returns the raw output from Tesseract OCR. This gives a bit more control over the parameters that are sent to tesseract.
EAST
An Efficient and Accurate Scene Text Detector, EAST, is a very robust deep learning method and an OpenCV tool that detects text in natural scene images. Its pipeline directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images, eliminating unnecessary intermediate steps (e.g., candidate aggregation and word partitioning).
Two outputs of the EAST network: 1. feature_fusion/concat_3 (detected text box) 2. feature_fusion/Conv_7/Sigmoid (confidence score)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import cv2
!pip install keras-ocr > /dev/null
from keras_ocr.tools import warpBox
model = "frozen_east_text_detection.pb"
net = cv2.dnn.readNet(model)
outputLayers = []
outputLayers.append("feature_fusion/Conv_7/Sigmoid")
outputLayers.append("feature_fusion/concat_3")
inpWidth = 640
inpHeight = 640
confThreshold = 0.7
nmsThreshold = 0.4
image = cv2.imread(imageName)
# Create a blob and assign the image to the blob
blob = cv2.dnn.blobFromImage(image, 1.0, (inpWidth, inpHeight), (123.68, 116.78, 103.94), True, False)
net.setInput(blob)
# Get the output using by passing the image through the network
output = net.forward(outputLayers)
scores = output[0]
geometry = output[1]
# Get rotated rectangles using the decode function described above
[boxes, confidences] = decode(scores, geometry, confThreshold) # see more details in Github Repos
indices = cv2.dnn.NMSBoxesRotated(boxes, confidences, confThreshold,nmsThreshold)
...
CRAFT
In terms of the recent works on scene text detection pipeline, (from CRAFT paper):
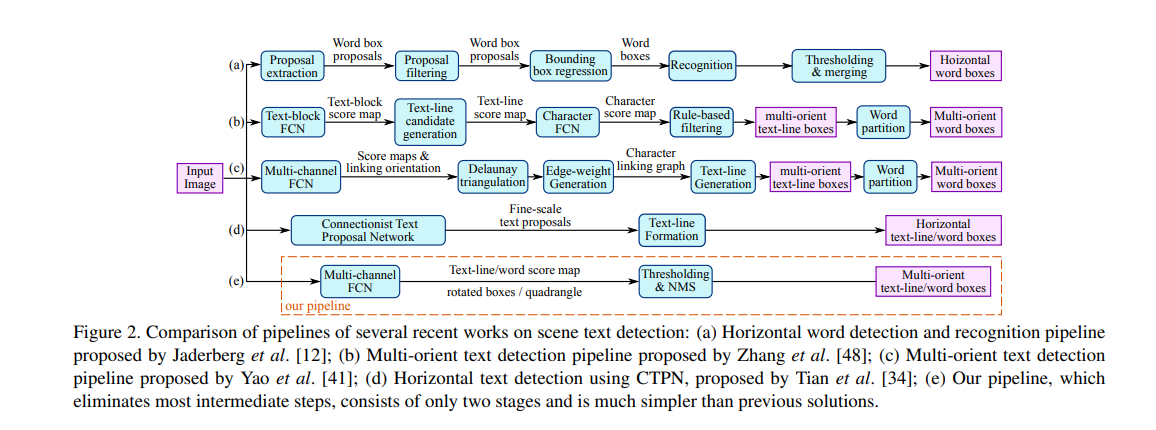
Character Region Awareness For Text Detection, CRAFT. The challenges associated with text detection, rather than regular object detection: huge aspect ratio variation, different fonts & backgrounds, skewed & curved text, and colored text.
Key idea in CRAFT: A word is a collection of letters -> Use the affinity between letters to detect words. The authors are repropose idea: Text detection problem -> Segmeantation problem
The outputs of the CNN in CRAFT: 1. Region Score; 2. Affinity Score. (they are grey-scaled image, or can say a 2-channels image).
If have the output label and input image, we can train a CNN; (input a image, output a mask). So how to generate the two maps for training data?
1. Similarity to Segmentation problem
Before that question, let’s look at the U-Net for semantic segmentation, and CRAFT use a very similiar network to solve this problem:
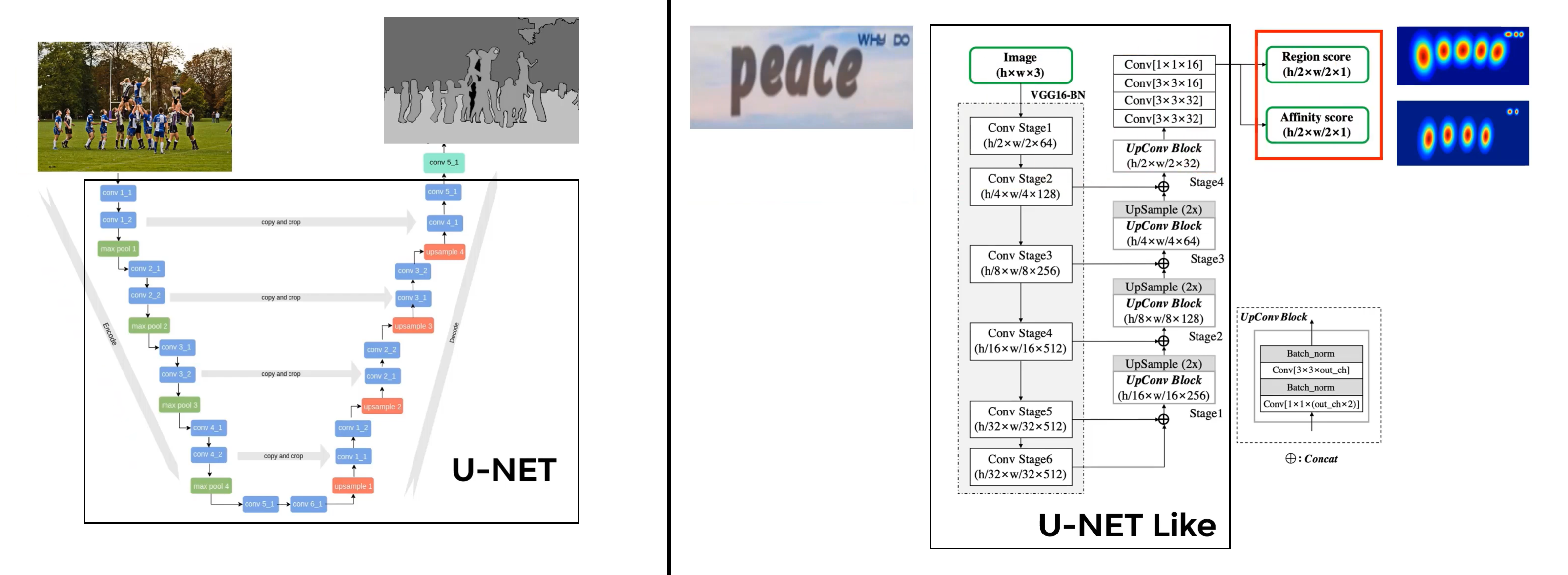
2. What’s the two maps menas?
 1. Region score
Basically indicates that these locations have a character in them and thery are centered at this point of highest probability.
1. Region score
Basically indicates that these locations have a character in them and thery are centered at this point of highest probability.
2. Affinity score Calculates the affnity between characters, or say the two letters are close together if there is high affinity at this location or part of same word.
3. Generate Ground Truth
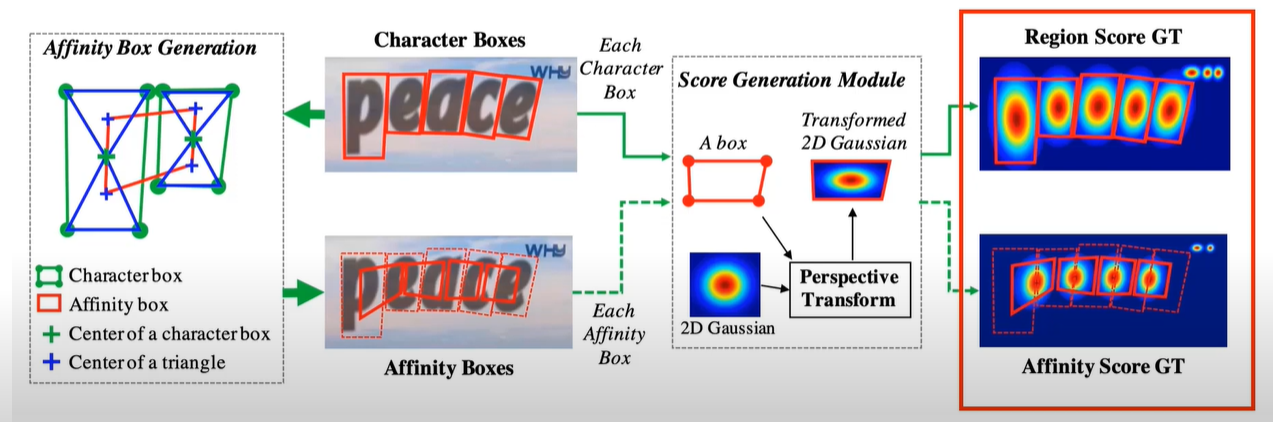 Suppose we’ve got the bounding boxs around the letter (character boxes), then the affinity boxes are generating as the figure above.
Suppose we’ve got the bounding boxs around the letter (character boxes), then the affinity boxes are generating as the figure above.
And the score generation module: warp a 2-D gaussain distribution based on the perspective transform between the boxes.
Problem: large public datasets contain only word level segmentation!
Solution: Synthesize the text examples.
The authors used a semi-supervised approach:
- crop out the word-level text
- run through the network they trained on Synthetic data to get various region score
- use watershed to get a segments
- fit bounding boxes for segments (pseudo ground truth)
but cannot trust this data completely. A clever solution:
If there is real data that is being used and also know what is this text, or the number of characters in this bounding box.
So once the above automated technique produces the right number of bounding boxes, given a higher weight compared to those segmentation were incorrect. So they can use the real data also.
Semi-supervised learning: using synthetic data to train CNN which is the supervised part. But for the real part they use these tricks which is not supervised.
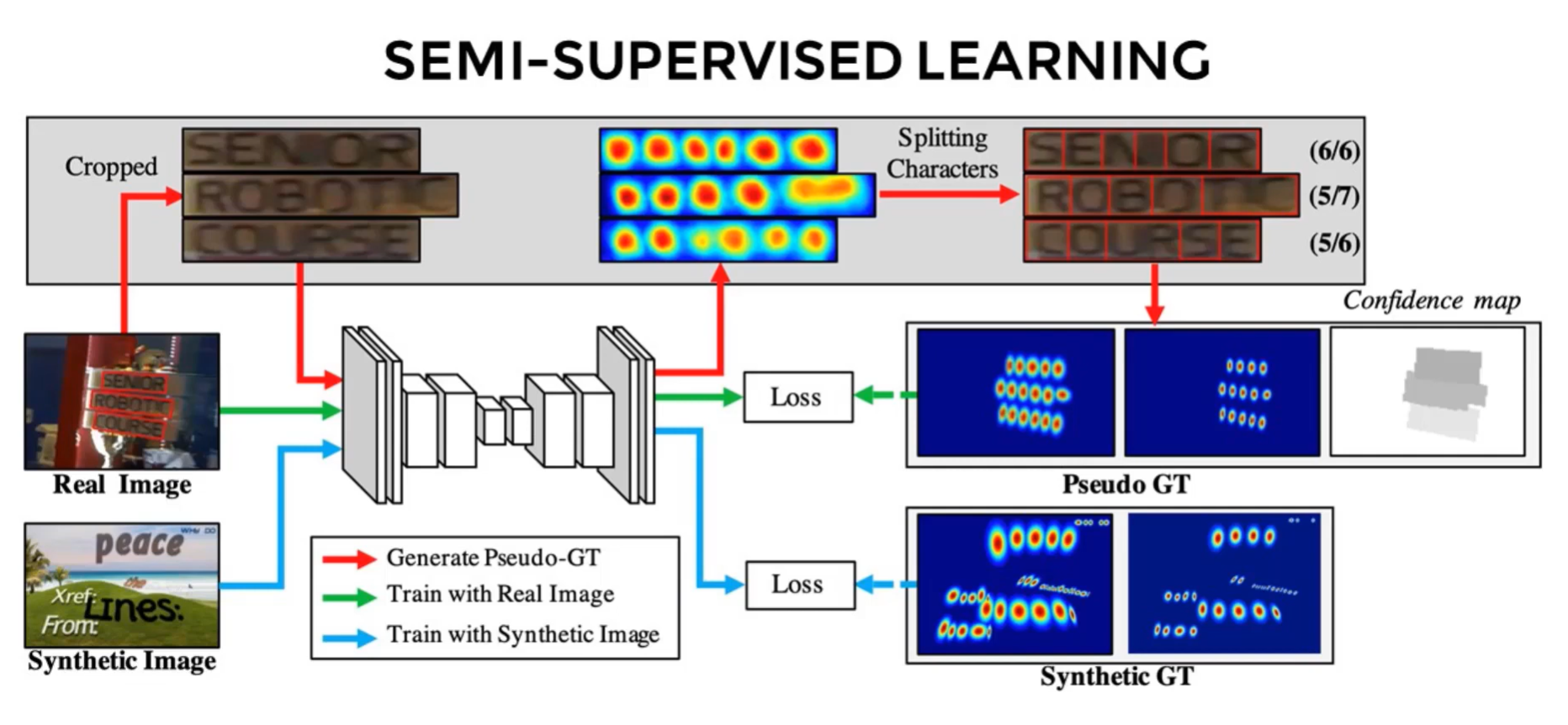
CRAFT Implementation
CRAFT model is carried by library Keras-OCR, which implemented Text Detection (CRAFT-2019) & Text Recognition (CRNN-2017) pipeline.
1. Install Keras-OCR Library:
!pip install keras-ocr > /dev/null
2. Text Detector:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import keras_ocr
import cv2
import glob
import matplotlib.pyplot as plt
%matplotlib inline
detector = keras_ocr.detection.Detector()
image = keras_ocr.tools.read('https://upload.wikimedia.org/wikipedia/commons/e/e8/FseeG2QeLXo.jpg')
detections = detector.detect(images=[image])[0]
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 10))
canvas = keras_ocr.tools.drawBoxes(image, detections)
ax1.imshow(image)
ax2.imshow(canvas)
OCR pipeline with Tesseract and CRAFT Text Detection
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import keras_ocr
import pytesseract
import cv2
import glob
import matplotlib.pyplot as plt
%matplotlib inline
def tess_recognize_from_boxes(image, detections, config):
predictions = []
# for each box
for i, box in enumerate(detections):
# get the cropped and algned image
cropped_warped = keras_ocr.tools.warpBox(image, box)
# Perform tesseract OCR on the cropped Text
text = pytesseract.image_to_string(cropped_warped, config=config)
# Store the text and the corresponding box
if text:
predictions.append((text, box))
return predictions
def modified_tesseract(image, config=('--psm 6')):
# Detect the Text boxes from the image using Keras-ocr
detections = detector.detect([image])[0]
# Run tesseract on boxes defined above
predictions = tess_recognize_from_boxes(image, detections, config)
return predictions
def display_boxes(image, boxes):
img = keras_ocr.tools.drawBoxes(image.copy(),boxes)
plt.figure(figsize=[10,10])
plt.imshow(img)
plt.show()
detector = keras_ocr.detection.Detector()
image = keras_ocr.tools.read("dlbook.jpg")
predictions = modified_tesseract(image)
fig,ax = plt.subplots(figsize = [10,10])
keras_ocr.tools.drawAnnotations(image, predictions, ax=ax)
Text Recognition using CRNN
Text Detection is done using the CRAFT algorithm published in CVPR-2019 and Text Recognition is done using the CRNN algorithm which was published in TPAMI-2017.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import keras_ocr
import cv2
import glob
import matplotlib.pyplot as plt
%matplotlib inline
image = keras_ocr.tools.read("dlbook.jpg")
pipeline = keras_ocr.pipeline.Pipeline()
prediction_groups = pipeline.recognize([image])
predictions = prediction_groups[0]
fig,ax = plt.subplots(figsize = [10,10])
keras_ocr.tools.drawAnnotations(image, predictions, ax=ax)
Comparing Tesseract vs CRNN based OCR
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
import keras_ocr
import pytesseract
import cv2
import glob
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
detector = keras_ocr.detection.Detector()
def tess_recognize_from_boxes(image, detections, config):
predictions = []
# for each box
for i, box in enumerate(detections):
# get the cropped and algned image
cropped_warped = keras_ocr.tools.warpBox(image, box)
# Perform tesseract OCR on the cropped Text
text = pytesseract.image_to_string(cropped_warped, config=config)
# Store the text and the corresponding box
if text:
predictions.append((text, box))
return predictions
def modified_tesseract(image, config=('--psm 6')):
# Detect the Text boxes from the image using Keras-ocr
detections = detector.detect([image])[0]
# Run tesseract on boxes defined above
predictions = tess_recognize_from_boxes(image, detections, config)
return predictions
pipeline = keras_ocr.pipeline.Pipeline(scale=1)
def compare_ocr(filename,figsize=(20,8)):
# Load Image
image = keras_ocr.tools.read(filename)
image_tess = image.copy()
image_kerasocr = image.copy()
# Perform OCR
tesseract_predictions = modified_tesseract(image_tess)
kerasocr_predictions = pipeline.recognize([image_kerasocr])
# Create a figure with a set of subplots
fig,axs = plt.subplots(ncols=3,nrows=1, figsize = figsize)
axs[0].set_title("Tesseract OCR")
axs[2].set_title("Keras OCR")
# Display Tesseract Output
keras_ocr.tools.drawAnnotations(image_tess, tesseract_predictions,ax=axs[0])
# Add a divider
axs[1].imshow(np.zeros((image.shape[0],2)))
axs[1].set_yticks([])
axs[1].set_xticks([])
# Display keras ocr output
keras_ocr.tools.drawAnnotations(image_kerasocr, kerasocr_predictions[0],ax=axs[2])
ROC Experience
- For document OCR ( like Scans of resume/invoice/receipts ), try with Tesseract ( using scaling helps in most cases ). It might work even without text detection
- For document OCR ( such as Books ) OCR preserves the order of text easily. If you use other methods, you need to handle that separately and might have to do some post-processing to get the text in the correct order.
- For natural scene images ( such as traffic signs, hoardings and detecting random texts ) - it is better to perform text detection since the text might be a small part of the image and then use either tesseract or CRNN or other methods - You should arrive at a conclusion only after doing some experiments with your data.